Log Analytics (如何利用AWS服務進行Log分析)
- 作者 -
Sam Tu, Business Development Manager, AWS
David Hung, Solutions Architect, AWS
![]()
[Challenge/Scenario]日誌分析是常見的大數據使用案例,讓您為數位行銷、應用程式監控、詐欺偵測、廣告技術、遊戲和 IoT 等各式各樣的應用程式,分析取自網站、行動裝置、伺服器、感應器等等的日誌資料。在這個專案中,您將使用 Amazon Web Services 建立一個端到端的日誌分析解決方案,用來收集、擷取、處理及載入批次資料和串流資料,並將處理過的資料近乎即時地放入使用者現用的分析系統中供他們使用。這個解決方案高度可靠、經濟實惠、可自動擴展以因應不同的資料量,而且幾乎不需要 IT 管理。
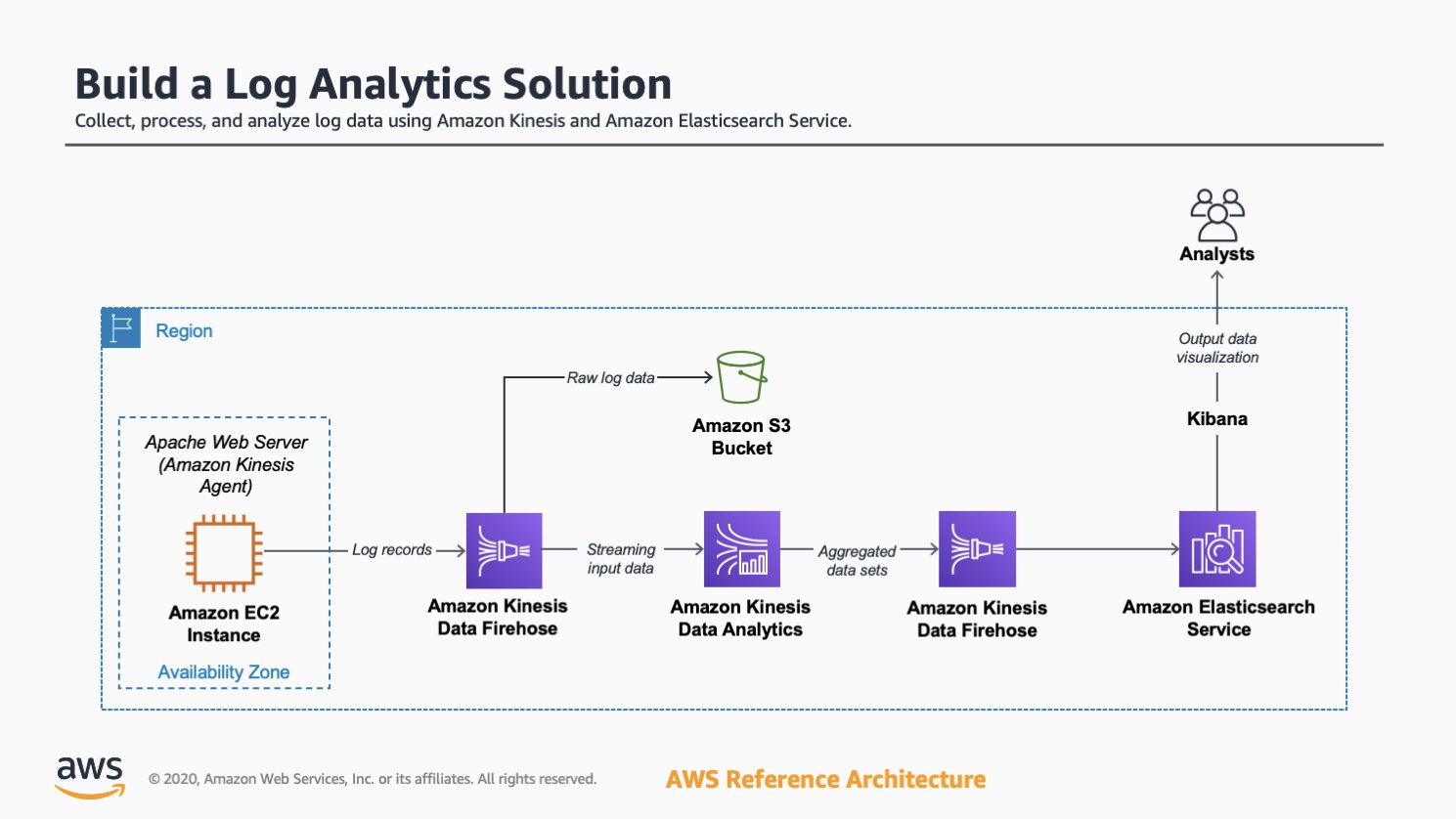
[SOP]步驟概覽
步驟一、建立 EC2 執行個體並產生日誌資料1.1 本教學部署區域為 us-east-1 (N. Virginia)
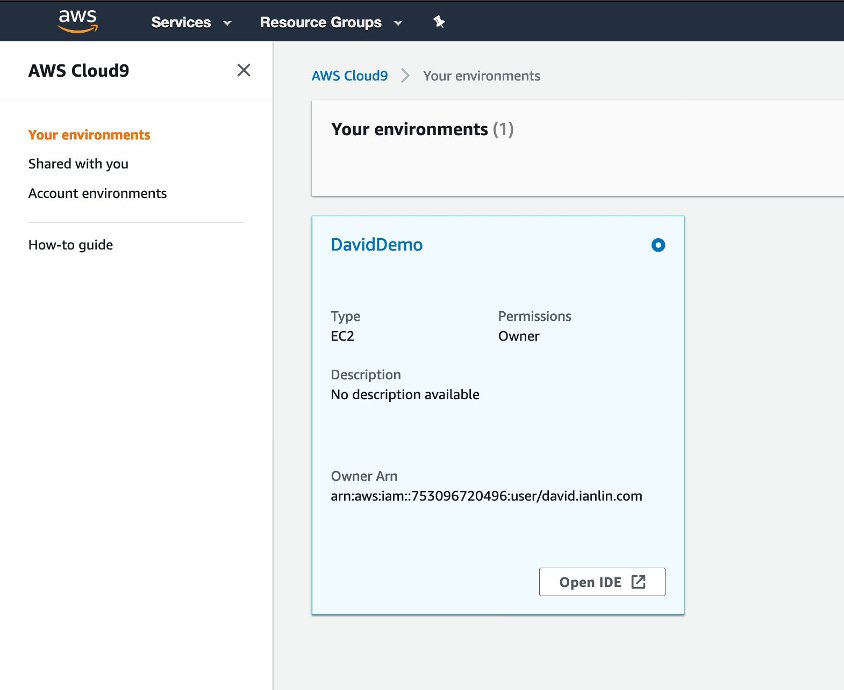
首先創建新的Cloud9 環境,只需輸入名稱,其他皆採用預設設定。 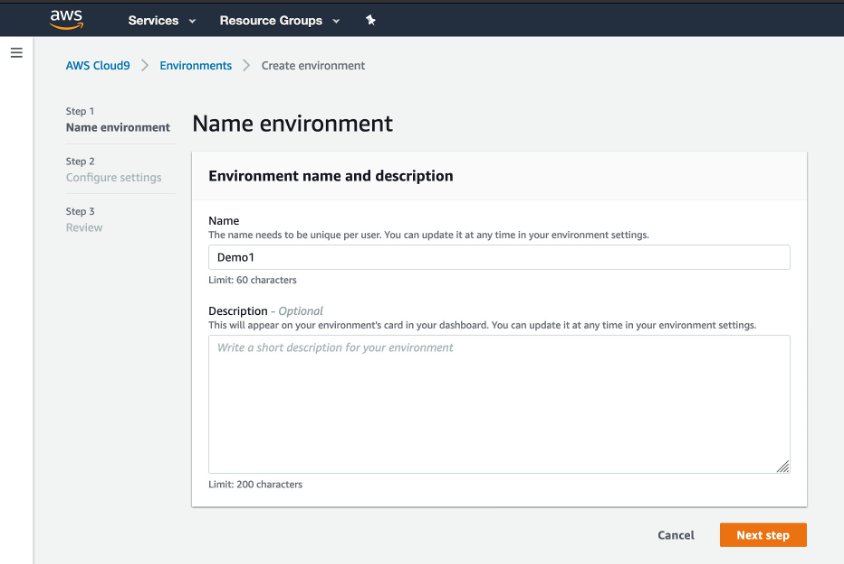 1.2 創建完成後,在Cloud9 介面按下 Open IDE 後,即可進入開發環境。
 1.3 進入 IDE 後,在 terminal 貼上以下指令安裝必要工具
sudo yum update -y 1.4 透過以下指令產生日誌資料,執行約 1-2 分鐘
1.5 透過以下指令即可找到剛產生的日誌檔
ls /tmp/logs
步驟二、建立 Amazon Kinesis Data Firehose Delivery Stream2.1 開啟 Amazon Kinesis 操作介面,按下 Get Started,並選擇 Kinesis Data Firehose,然後點選 Create Delivery Stream 進入建立介面
 2.2 在 Name and source 階段:
 2.3 在 Process records screen 階段,保留所有預設設定,進入下一步
2.4 在 Choose a destination screen 階段:
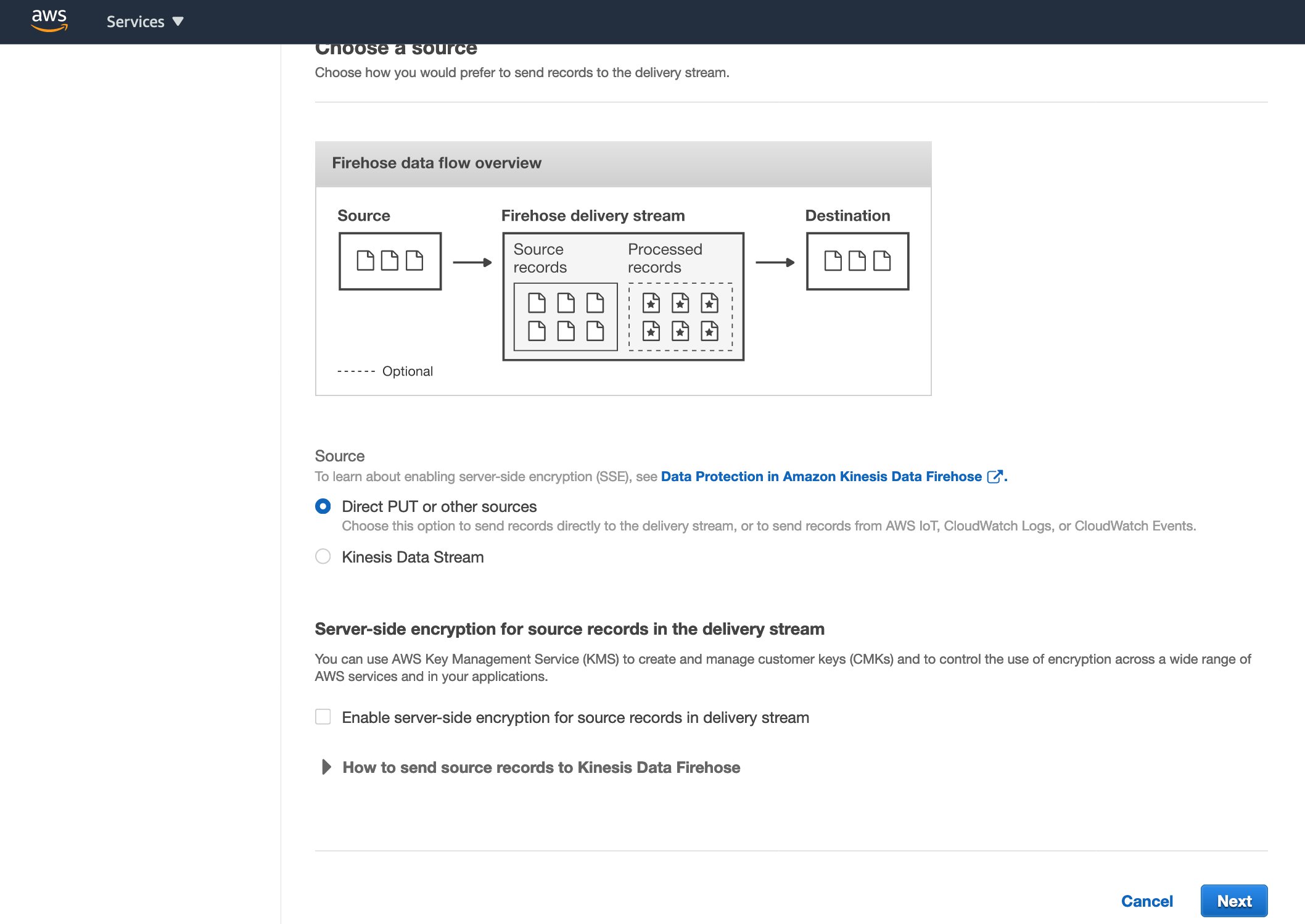
2.5 在 Configure settings 階段,Permissions 選項中,選擇 Create or update IAM role,點選下一步,並於 Review 階段點選 Create Delivery Stream
 步驟三、在 AWS Cloud9 上 安裝 Kinesis Agent3.1 進入 AWS Cloud9 IDE,於 terminal 中輸入以下指令安裝 Kinesis Agent
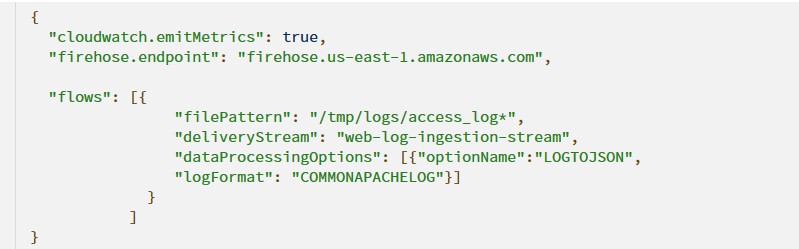
3.2 修改 Kinesis Agent 設定檔:
3.3 透過以下指令啟動 Kinesis Agent:
步驟四、建立 Amazon Elasticsearch 叢集4.1 開啟 Amazon Elasitcsearch Service 操作介面,選擇 Create a new domain 建立新的 Amazon Elasticsearch 叢集
4.2 在 Choose deployment type 階段,Deployment type 選擇 Development and testing,其餘保持預設值,前往下一步
4.3 在 Configure domain 階段,Elasticsearch domain name 填入 web-log-summary 作為叢集名稱,其餘保持預設值,前往下一步
4.4 在 Configure access and security 階段:
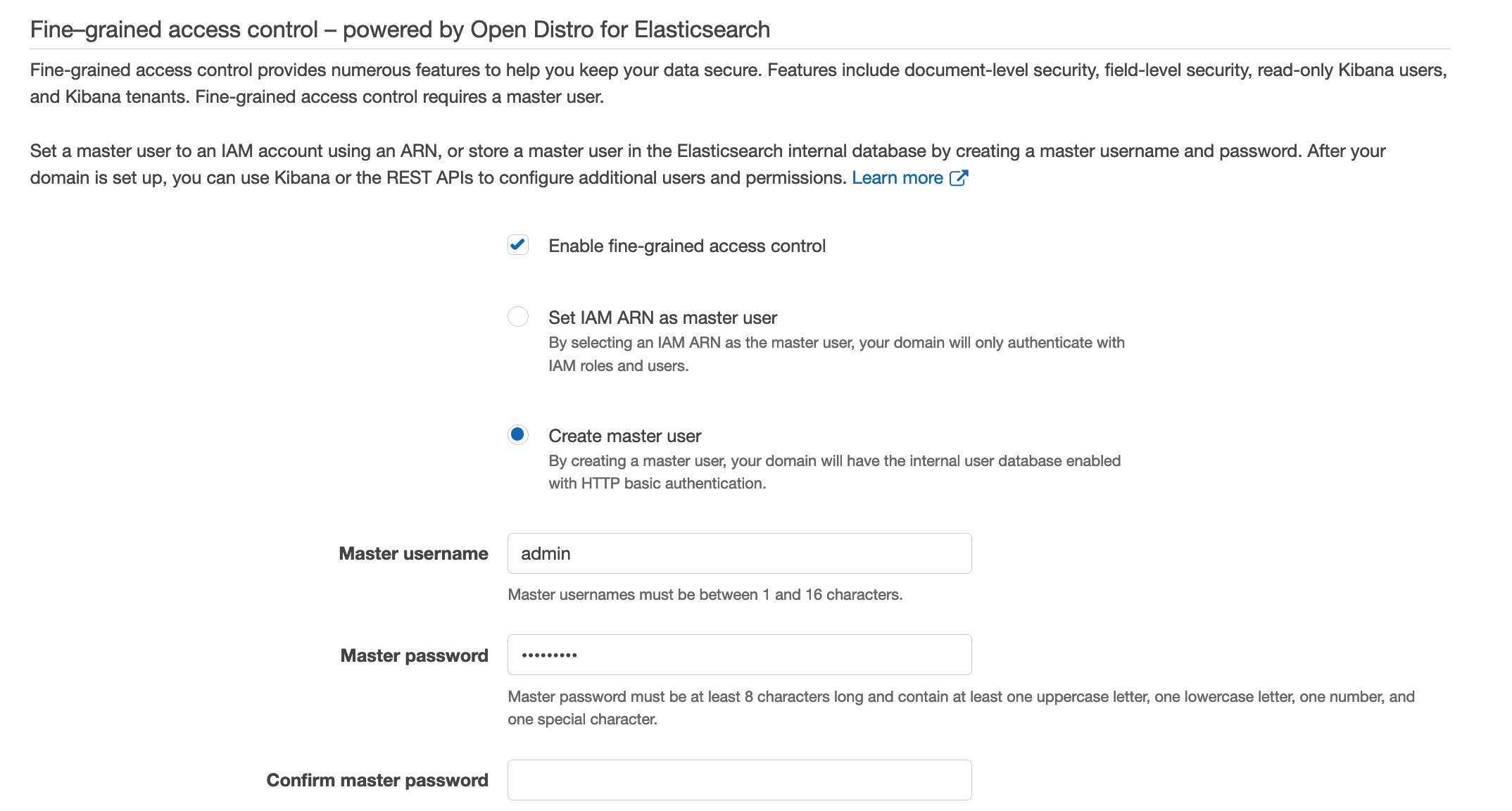
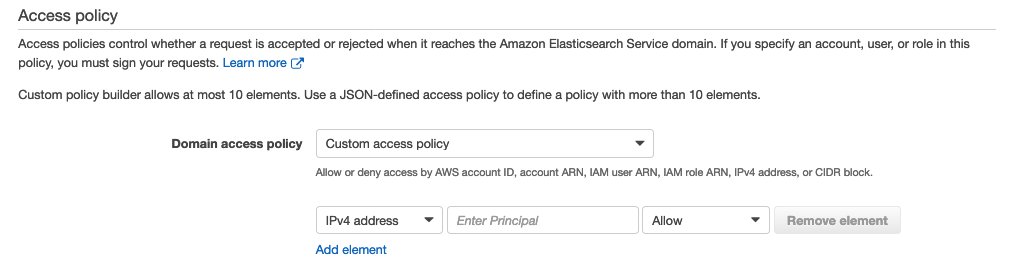 步驟五、建立第二個 Amazon Kinesis Data Firehose Delivery Stream5.1 開啟 Amazon Kinesis 操作介面,按下 Get Started,並選擇 Kinesis Data Firehose,然後點選 Create Delivery Stream 進入建立介面
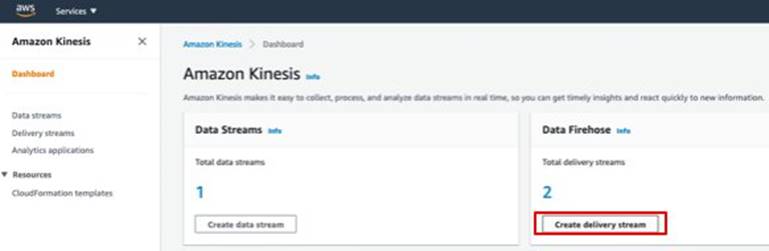 5.2 在 Name and source 階段:
5.3 在 Process records screen 階段,保留所有預設設定,進入下一步
5.4 在 Choose a destination screen 階段:
5.5 在 Configure settings 階段,Permissions 選項中,選擇 Create or update IAM role,點選下一步,並於 Review 階段點選 Create Delivery Stream,即可完成建立。
5.6 為 delivery stream 新增 Elasticsearch 訪問權限:
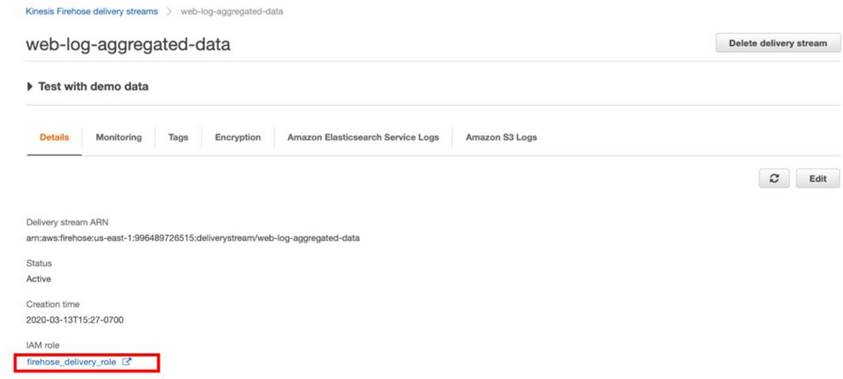
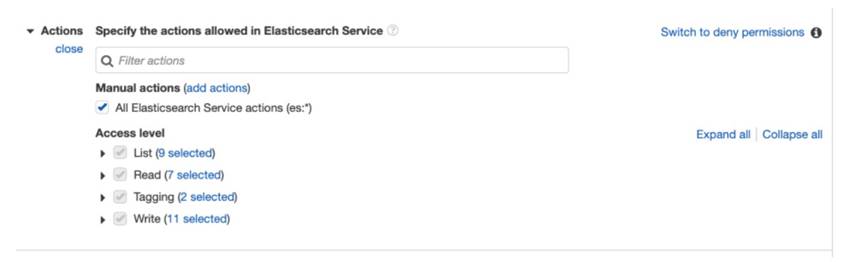
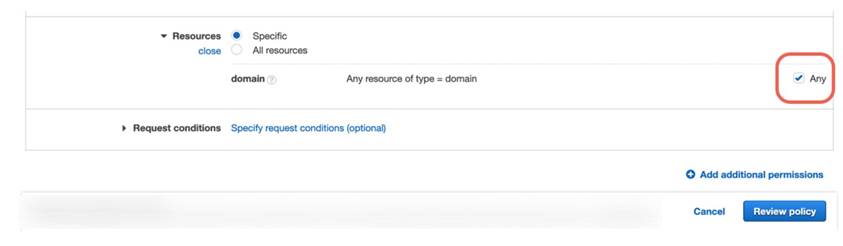 步驟六、建立 Amazon Kinesis Data Analytics Application6.1 前往 Amazon Kinesis Analytics 操作介面,並點選 Create new application,取名為 web-log-aggregation-tutorial,使用預設值完成建立
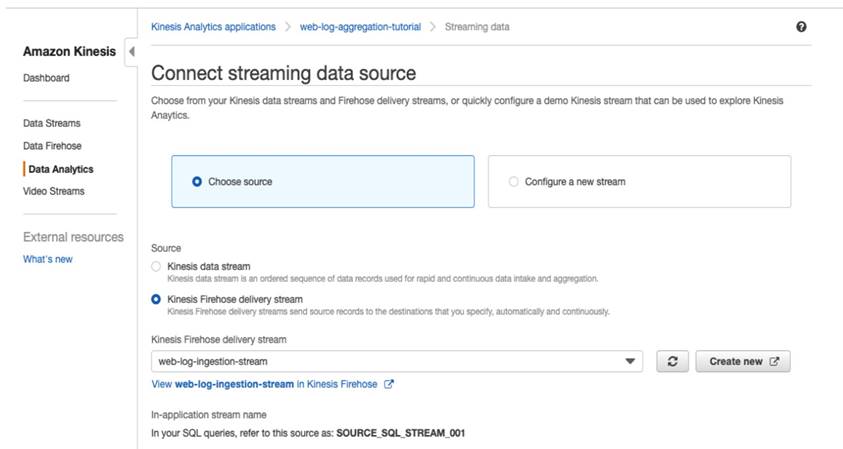
6.2 選擇 Connect streaming data,在 Source 選擇 Kinesis Firehose delivery stream 並指定步驟二建立的 web-log-ingestion-stream
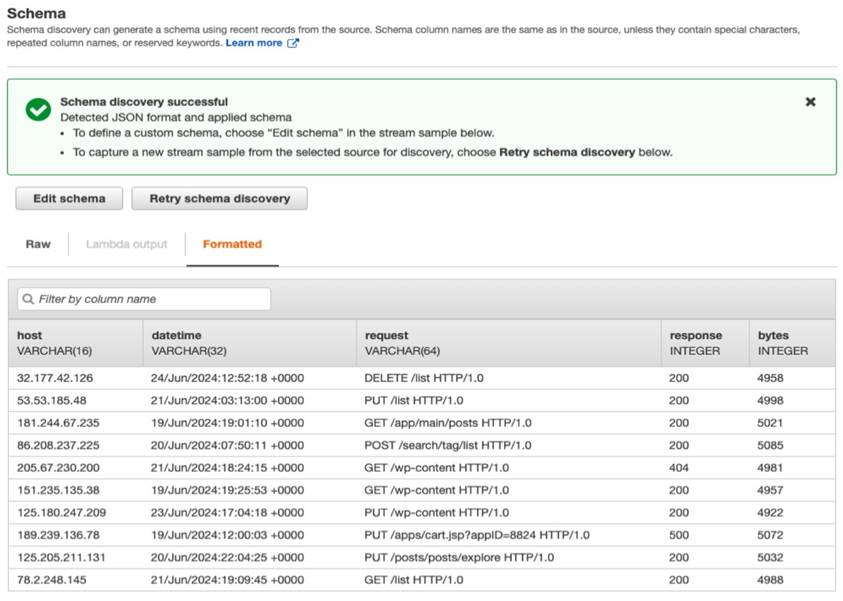
 6.3 在下方找到 Schema 部分,選擇 Discover schema,等待數秒後,Amazon Kinesis Analytics 會自動偵測數據格式,並呈現以下畫面,點選 Save and continue 完成
 6.4 進入 SQL editor,點選 Yes, start application,在 SQL editor 中,填入以下 SQL 程式碼:
6.5 選擇 Save and run SQL,等待約一分鐘後,將會呈現查詢結果,此時點選 Destination,選擇 Connect to a destination,然後在Kinesis Firehose delivery stream 中找到並選取 web-log-aggregated-data
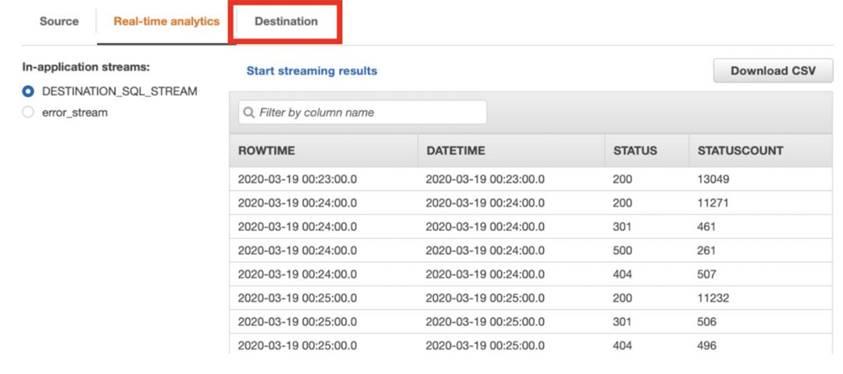 6.6 在 In-application stream 中,選擇 DESTINATION_SQL_STREAM,其餘保留預設值,完成建立
步驟七、使用 Kibana 分析數據7.1 首先前往 步驟四建立的 Elasticsearch 叢集,在 Overview 頁面中找到 Kibana 連結,輸入先前設定的帳號密碼,進入 Kibana 操作介面
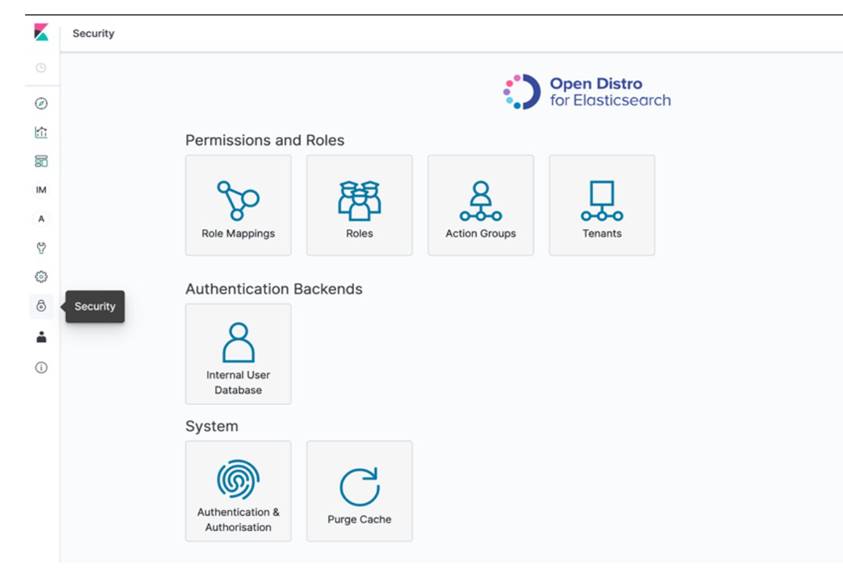
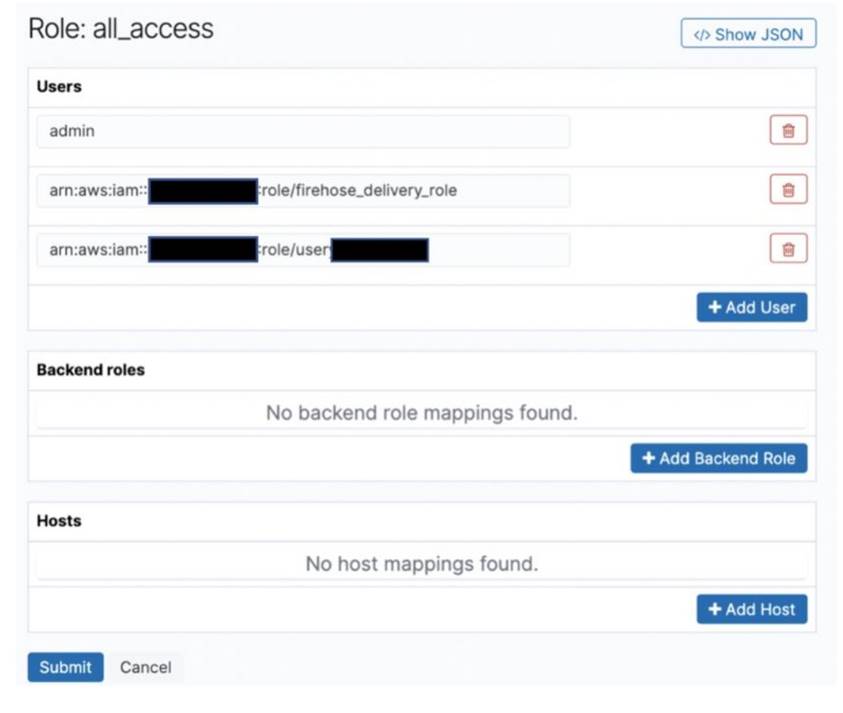
7.2 點選左下方的 Security 圖示,進入安全設定頁面,點選 Role Mapping → all_access → add user 將步驟五建立 Kinesis Delivery Stream 之 IAM Role ARN 貼上,授與該 Delivery stream 連接 Elasticsearch 之權限
  7.3 前往 Cloud9 頁面,執行以下程式碼發送日誌資料
同時在另一個 terminal 中確認 Kinesis Agent 已經啟動
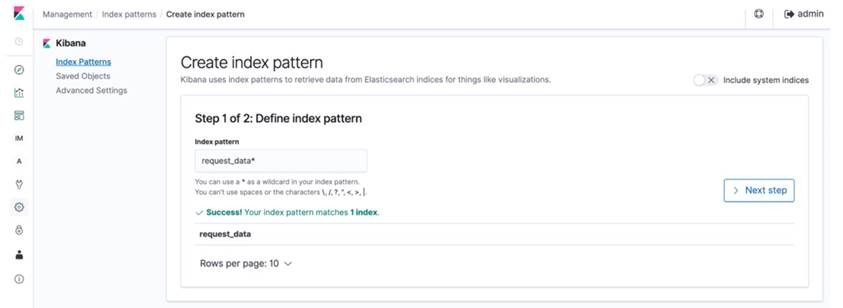
7.4 等待約 10 - 15 分鐘,產生足夠資料量並發送至 Elasticsearch 後,點選左方的 Dashboard,在 Define index pattern 中輸入 request_data,點選 Next step → Create index pattern
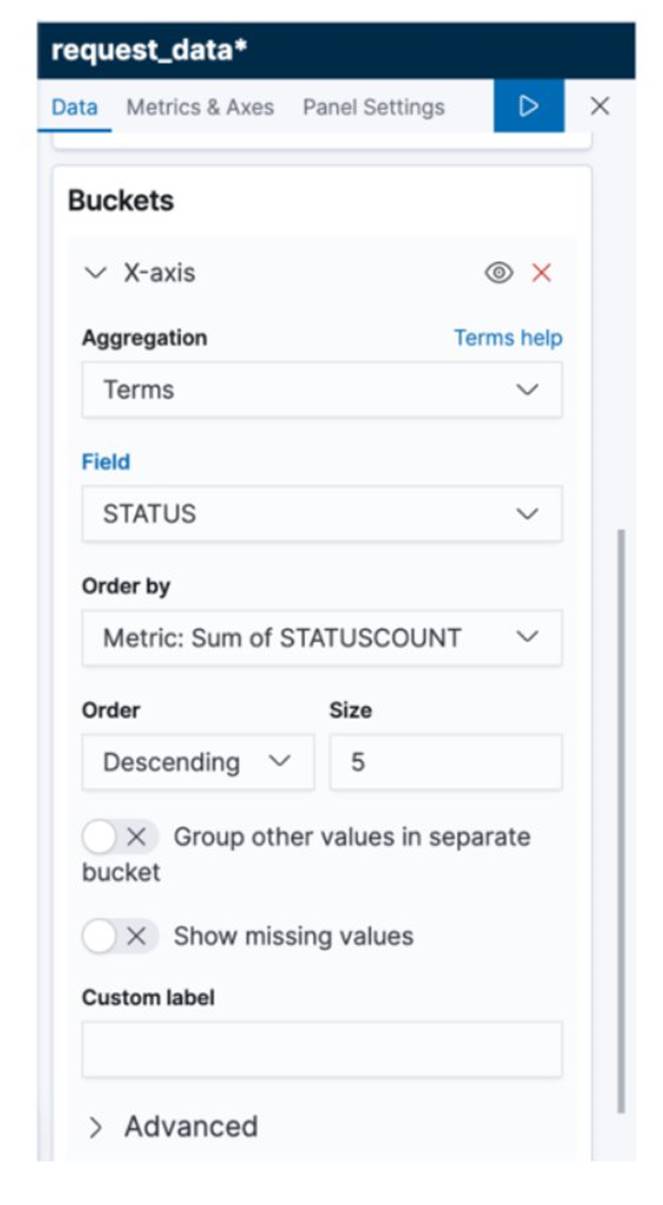
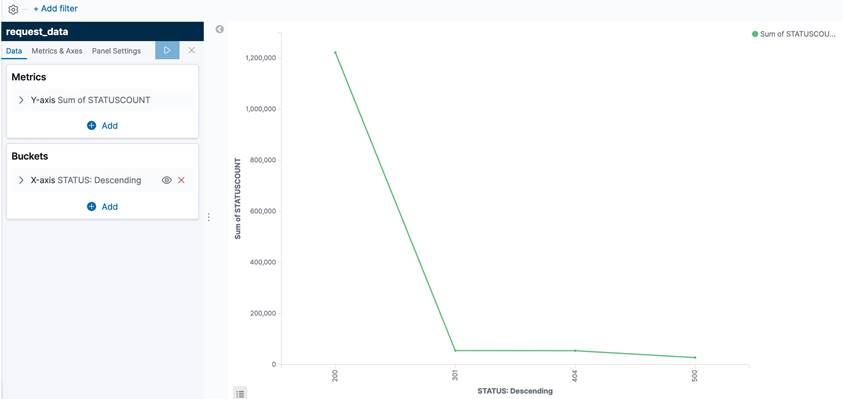
 7.5 接著點選左方的 Visualize 圖示,進入資料視覺化介面,進行以下步驟:
 [FAQ]Q1: 為何我無法成功透過 Amazon Kinesis Data Firehose 發送資料至 Elasticsearch 叢集?
A1: 首先透過 Kinesis Data Firehose 內建的 monitor 進行監控,觀察
DeliveryToElasticsearch.Success 項目,確認是否有資料成功發送,若發送失敗,可前往 CloudWatch log 檢視失敗原因,具體的錯誤排除流程可以參考 Amazon Kinesis Data Firehose 官方文件 。Q2: 如何增加 Cloud9 儲存空間?
A2: 增加 Cloud9 儲存空間的方法,請參考此官方文件 https://docs.aws.amazon.com/cloud9/latest/user-guide/move-environment.html
|