データのフライホイール戦略の概要
データのフライホイール戦略は、ビジネスリーダーやテクノロジーリーダー向けの包括的かつ付加的なアプローチです。企業や組織がデータから最大限の価値を引き出すことを可能にします。
レガシー (従来の) データベースから
脱却する
データホイールを開始するための最初のステップは、レガシー (従来の) 商用データベースの制約から解放されることです。レガシーデータベースは専有するためコストがかかり、ロックインが発生します。さらにライセンス体系が複雑で、頻繁な監査が発生します。このような理由から、レガシーデータベースでは、ビジネスの推進を加速するためのデータフライホイールの構築に必要な、スケーラビリティ、柔軟性、コスト効率を実現することは困難です。
フルマネージド型データベースと分析サービスで時間とコストを削減
データベースや分析インフラストラクチャの管理は煩雑で時間がかかります。AWS のフルマネージド型サービスに移行すれば、インフラストラクチャの管理ではなく、イノベーションや新しいアプリの構築に時間をかけることができます。
モダンデータウェアハウジングで処理を高速に
最新のクラウドベースのデータウェアハウジング戦略により、より多くのデータの保存、処理、分析を、迅速かつ効率的に行うことができます。まるでデータレイクのように、つまり、すべてのデータを保存し新しい分析方法を可能にする一元化されたレポジトリを扱うように、より柔軟なアーキテクチャを活用できます。
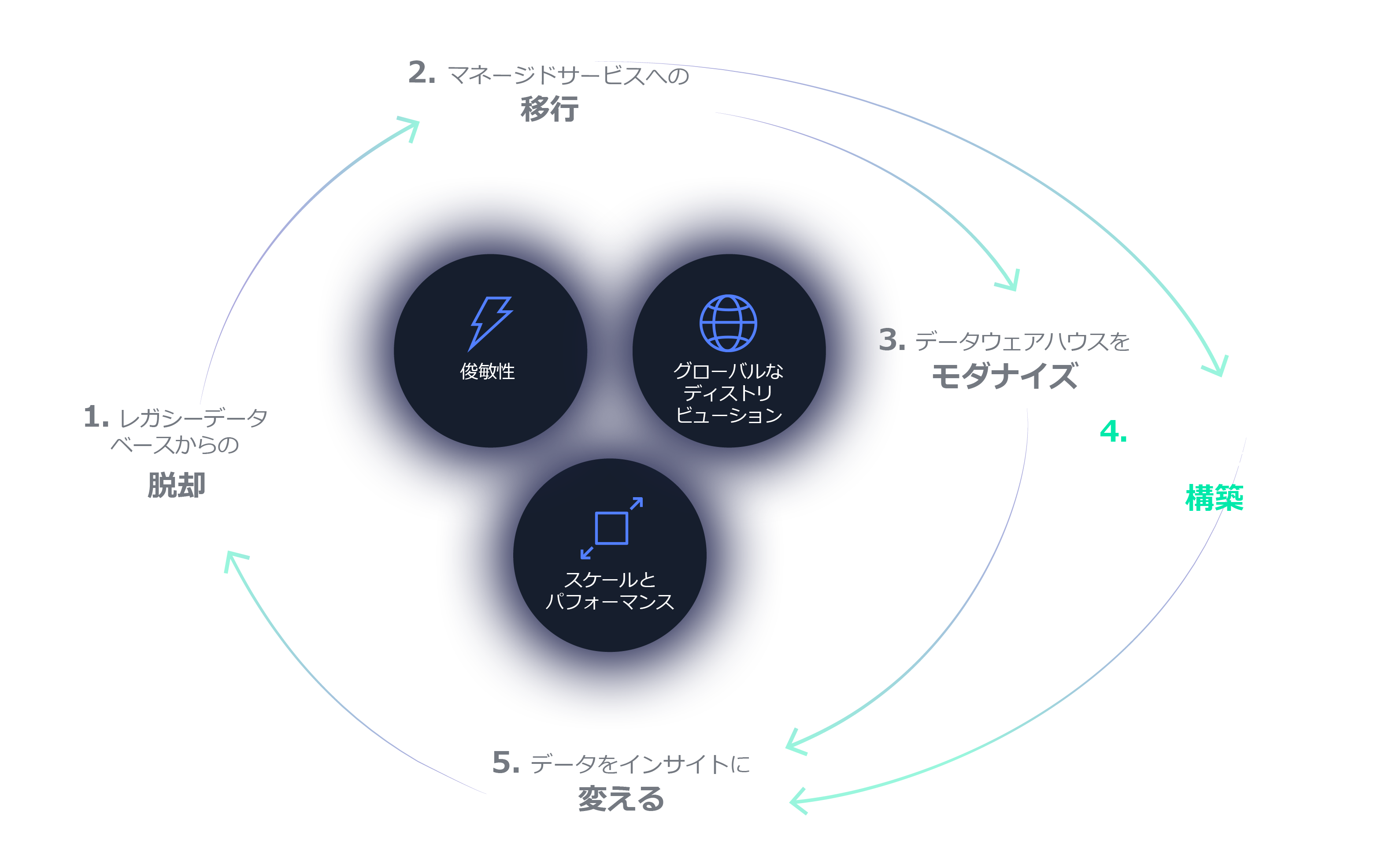
モダンアプリケーションを構築して推進力を向上
AWS を使えば、15 以上の専用データベースから選択しモダンアプリケーションを構築できます。ビジネスとともに成長する、高パフォーマンスでスケーラブル、可用性の高いアプリケーションを構築するための、業務に最適なツールを提供します。
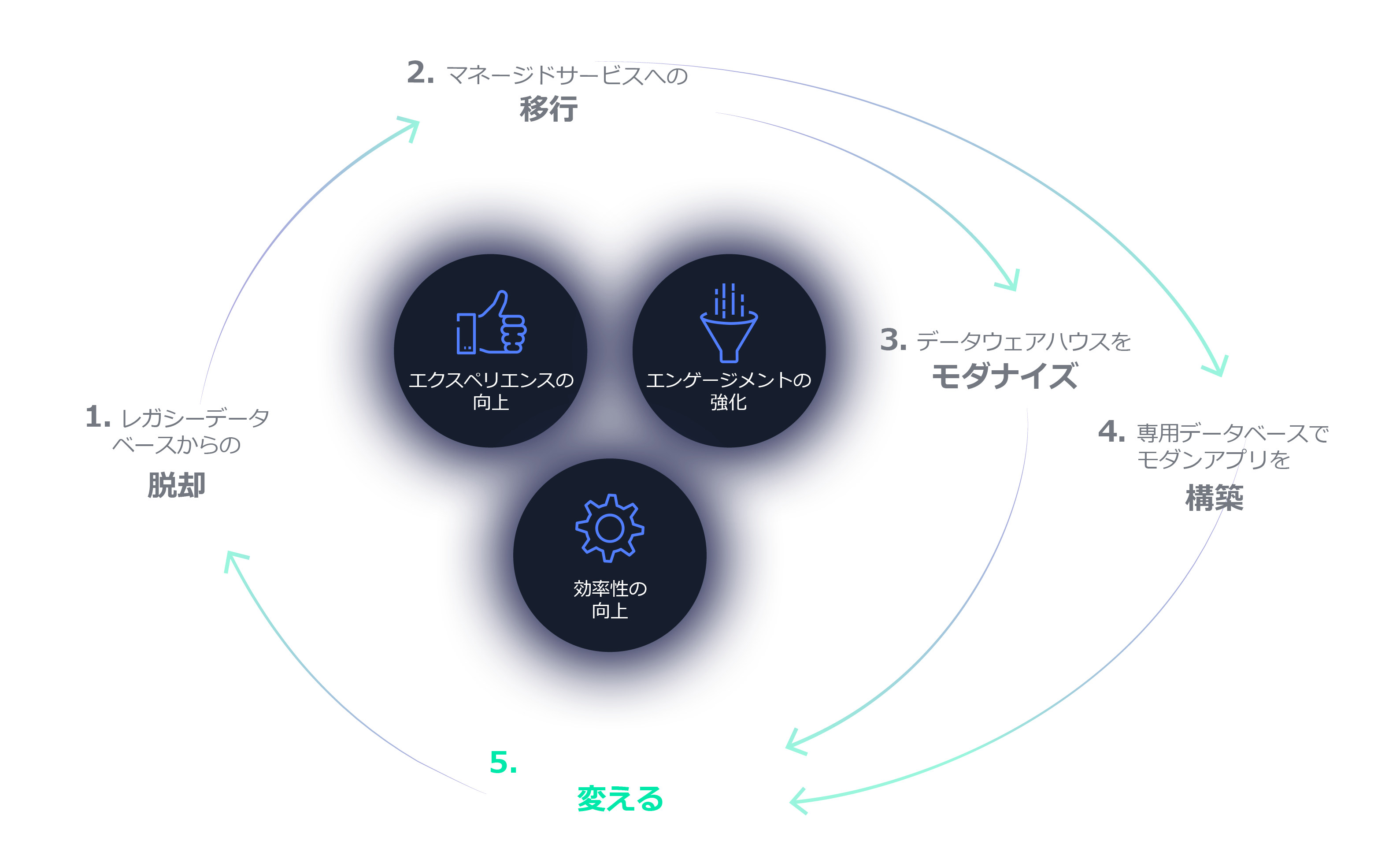
データからより多くの価値を獲得
早速、クラウド上のデータを活用してみましょう。ここは、サイロや、不完全な分析とは無縁の世界です。今日のビジネスでは、データレイク、クラウド分析、機械学習を通じて、スマートで正確なインサイト (洞察) をより迅速に収集し、エンドユーザーがあらゆるデバイスやアプリケーションからデータを表示して可視化することができます。
継続的なビジネス推進力を創造する
熱力学上、永久運動は不可能とされています。しかし、物理学の法則はビジネスにも当てはまるのでしょうか? 適切に運用すれば、データは自立的で終わりのない、加速する促進力を組織に生み出すことができます。
フライホイール戦略を採用する理由
作家のジムコリンズ氏によって知られるようになったフライホイール (弾み車) とは、相互に補強および推進し合ういくつかの主要イニシアチブによって構成される、自己強化型のループのことで、これにより長期的なビジネスを構築します。ジェフ ベゾスは 90 年代初めに、Amazon フライホイールを使用して Amazon.com の最初のアイデアを考え出しました。これは、選択の幅を広げてコストを削減することでカスタマーエクスペリエンスを向上させる、成長とスケーリングを利用した経済的な原動力です。
データフライホイールの構築を成功させる
データフライホイール戦略の最もユニークな特徴の 1 つは、「1 つの要素」だけが原動力となっていないことです。組織がそのような根本的かつ基本的なソリューションを探そうとしても、失敗するでしょう。データフライホイールは、協調して働く多くのコンポーネントによって機能しており、それぞれの部分の合計よりも大きな相乗効果を生み出します。これら各コンポーネントの開発に時間をかけ、どのフェーズにおいても関連性の最も高いテクノロジーや手順を実装する組織は、データフライホイールの構築において最も成功する可能性が高いと言えます。


レガシー (従来の) 商用データベース
-

高コスト
レガシーデータベースはコストが高く、ライセンス料金、メンテナンス、サポートに、より多くの費用が発生します。
-

独自仕様
独自仕様のデータベースはアプリケーションをロックインし、イノベーションに制約が生まれます。
-

ロックイン
独自仕様のデータベースは、契約によりロックインされ、必要ないものを購入せざるを得ない場合もあります。
-

複雑なライセンス体系
複雑な契約ライセンスにより柔軟性が制限され、予期しないコストが発生します。
-

予定外の監査
頻繁な監査により、導入時に予定していなかった計画外のコストが生じる場合があります。
オープンソースデータベースへの移行
従来の商用データベースが抱える課題を解決するため、ユーザーは MySQL、PostgreSQL、MariaDB などのオープンソースのデータベースへできるだけ早く移行しようとしています。ただし、ユーザーはハイエンドな商用データベースのパフォーマンスと可用性、オープンソースデータベースのシンプルさとコスト効率性も同時に求めています。
データベースをクラウドへ移行する際に考慮すべき重要事項とは?
両方の長所を最大限に活用する
AWS を使えば、オープンソースのシンプルさやコスト効率をそのままに、商用データベースのパフォーマンスや可用性を得ることができます。Amazon Aurora は、MySQL や PostgreSQL と互換性があり、標準のオープンソースデータベースよりも格段に高速なパフォーマンスを、商用ソリューションの 1/10 のコストで提供するリレーショナルデータベースです。Amazon DynamoDB は、規模に関係なく数ミリ秒台のパフォーマンスを実現する、キーバリューおよびドキュメントデータベースです。また、Amazon Redshift は、現在、最速かつ最もコスト効率の高い、クラウドデータウェアハウスです。
フルマネージド型データベースを採用する理由
データベース管理は、ビジネスで大きな負担になることがあります。ハードウェアの設置とソフトウェアのインストールに加えて、データのレプリケーションと高可用性のためのデータベースのパッチ適用、バックアップ、複雑なクラスター設定、煩雑なキャパシティー計画、コンピューティングとストレージのためのクラスターのスケーリングなどを考慮しなければなりません。
Amazon RDS によりパフォーマンスを向上させ、時間を短縮
多くの場合、企業や組織は Amazon Relational Database Service (RDS) に移行することで、マネージド型サービスへのシフトを開始します。RDS は、MySQL や PostgreSQL などのオープンソースエンジンをはじめ、Oracle や SQL Server など、任意のデータベースエンジンを実行できるフルマネージド型のソリューションです。Amazon RDS は、データベースのスケールとパフォーマンスを向上させ、ハードウェアのプロビジョニング、データベースのセットアップ、パッチ適用、バックアップなどの時間のかかる管理作業を自動化します。
-

管理が簡単
ハードウェア、OS、データベースソフトウェアを簡単にデプロイして管理します。また、組み込みのモニタリング機能を活用できます。
-

高パフォーマンスでスケーラブル
数回のクリックと最小のダウンタイムでコンピューティングとストレージをスケールできます。
-

可用性と耐久性
マルチ AZ の自動データレプリケーションと自動化されたバックアップ、スナップショット、フェイルオーバーを利用できます。
-

高いセキュリティとコンプライアンス
保管時のデータおよび転送中のデータを暗号化し、コンプライアンスを確保します。
すべてのデータベースをクラウドに移行
さらに多くのメリットを得るために、リレーショナルデータベースと非リレーショナルデータベースの両方を、クラウド上のフルマネージド型サービスに移行します。
最新の分析アーキテクチャを作成し
データを最大限活用する方法とは?
リレーショナルデータベース
高価な Oracle や SQL Server データベースから Amazon Aurora に移行します。標準の MySQL および PostgreSQL から Amazon RDS に移行してください。
非リレーショナルデータベース
ドキュメントおよびキー値ストアを Amazon DynamoDB へ、MongoDB などのドキュメントデータベースを Amazon DocumentDB へ、Cassandra データベースを Amazon Keyspaces へ (Apache Cassandra の場合) 移行します。
フルマネージド型分析が必要な理由
他のデータベースサービスと同じく、AWS が提供するフルマネージド型分析サービスでは、コストを削減し、イノベーションにより多くの時間を確保することができます。また、動的なスケーラビリティ、高速な処理、簡単な視覚化、高い可用性と耐障害性、強力なセキュリティも実現します。
-

Hadoop および Spark
オンプレミスの Hadoop および Spark デプロイを Amazon EMR に移行して、時間とコストを削減してください。
-

運用分析
Elasticsearch、Logstash、Kibana (ELK) オンプレミスは、Amazon Elasticsearch Service に移行して時間とコストを削減することができます。
-
リアルタイム分析
Apache Kafka デプロイは、Amazon Managed Streaming for Apache Kafka (MSK) に移行できます。また Amazon Kinesis は、データストリームを準備、ロード、分析して、データストアや分析ツールですぐに使用できるようにします。
従来のデータウェアハウジングの課題
従来のオンプレミスのデータウェアハウジング戦略では、最新のビジネスニーズを満たすことは困難です。
-

スケールしない
ストレージやコンピューティング性能が足りなくなる度に、より大型で強力なハードウェアを購入する必要があります。
-

遅い
処理と分析の前に、データを別の分析システムに移動する必要があります。これはリアルタイム分析を行うには遅すぎます。
-

高コスト
レガシーデータベースは、高コストかつ専有的で、厳しいライセンス条件が適用される場合があります。
-

柔軟性が低い
ウェブサイト、モバイルアプリ、インターネット接続デバイスで生成された新しいデータ形式に適切に対応できません。
-
サイロ化
データレイクや Hadoop に保存されたデータを組み込むことができません。
-

複雑
分析は、少数の BI 専門家による、履歴データに関する運用レポートに制限されます。
最もよく使われている高速なクラウドデータウェアハウスを活用しましょう
Amazon Redshift でデータウェハウスをモダナイズすれば、パフォーマンス、スケール、データレイクとの深い統合により、データを最大限活用することができます。
分析主導型の組織に変革する方法、および、モダンデータウェアハウスとデータレイクソリューションによって変革を実現する方法とは?
-

実績多数
数十万のお客様が Amazon Redshift を利用しています。
-
統合性
データウェアハウス、データレイク、および運用データベース全体でペタバイトのデータのクエリを実行します。
-

高速
Amazon Redshift は、他のクラウドデータウェアハウスよりも最大 3 倍高速です。
-

高いコスト効率
Amazon Redshift は、他のクラウドデータウェアハウスよりも最大 50% 安価です。
アプリケーション設計のルールが変更に
モダンアプリケーションの設計では、データベースに関する新しい一連の要件があります。今日のアプリは、テラバイト単位からペタバイト単位のデータにスケールし、数百万人の同時接続ユーザーに対応して、ミリ秒またはマイクロ秒単位のレイテンシーでパフォーマンスを提供するためのデータベースを必要としています。
アプリケーションに対する要件の一例
- ユーザー: 100 万人以上
- データボリューム: TB-PB-EB
- 場所: グローバル
- パフォーマンス: ミリ秒-マイクロ秒単位
- リクエスト率: 毎秒数百万
- アクセス: ウェブ、モバイル、IoT、デバイス
- スケール: スケールアップ/ダウン、スケールアウト/イン
- 料金: 従量課金制
- デベロッパーアクセス: インスタント API アクセス
すべてのデータを保存し、保持する
-

データベース戦略の変更
すべてにリレーショナルデータベースを使用する汎用型のアプローチでは、もはや十分ではありません。
-

複雑なアプリを分解する
適切なアーキテクチャとスケーラビリティを確保するには、すべてのアプリケーションコンポーネントを調べる必要があります。
-
高度に分散したアプリケーションを構築する
複雑なアプリケーションをマイクロサービスに分解します。
ワークロードに最適なのはどのデータベースでしょうか
通常、ジョブに最適なツールはユースケースごとに異なります。そのため、デベロッパーは多様な専用データベースを使用して、高度に分散したアプリケーションを構築する必要があります。
最も一般的なアプリケーションワークロードの利点とユースケースを以下でご紹介します。

専用データベースの種類と、業務に応じた最適なデータベースを見つける方法とは?
リレーショナルデータベース管理システム (RDBMS) において、データは列と行の表形式で保存され、構造化クエリ言語 (SQL) を使用してクエリされます。テーブルの各列は属性を、テーブルの各行はレコードを表し、テーブルの各フィールドはデータ値を表します。リレーショナルデータベースは、1) 基になるスキーマを知らなくても SQL を簡単に学習および使用でき、2) 本文全体を指定しなくてもデータベースエントリを変更できるため、広く使用されています。
利点
-
構造化データに適している
-
ACID トランザクションや複雑な結合をサポートしている
-
組み込みのデータ整合性
-
データの正確性と一貫性
-
無制限のインデックス作成
ユースケース
-
ERP
-
CRM
-
財務
-
トランザクション
-
データウェアハウス
キーバリューデータベースは、簡単なキーバリューメソッドを使用して、キーが一意の識別子として機能するキーバリューペアのコレクションとしてデータを保存します。キーバリューは、単純なオブジェクトから複雑な複合オブジェクトに至るまで、何でもかまいません。増加する、または予測不可能なワークロードに対応するためにインスタントスケールを必要とするアプリケーションに適しています。
利点
-
シンプルなデータ形式により書き込みと読み取りを高速化
-
値は、JSON、柔軟なスキーマなど、種類を問わない
ユースケース
-
リアルタイム入札
-
ショッピングカート
-
製品カタログ
-
カスタマー設定
ドキュメントデータベースでは、データは JSON のようなドキュメントに保存され、JSON ドキュメントはデータベース内の第 1 級オブジェクトです。ドキュメントはデータ型や値ではなく、データベースの重要な設計ポイントです。これらのデータベースは、デベロッパーがアプリケーションコードで使用するのと同じドキュメントモデル形式を使用するため、デベロッパーは簡単にデータを保存してクエリできます。
利点
-
柔軟、半構造化、階層的
-
データベースはアプリケーションのニーズに合わせて進化
-
階層データおよび半構造化データの表現が容易
-
高速クエリのための強力なインデックス作成
-
ドキュメントはオブジェクト指向プログラミングに本質的に対応
-
永続層へのデータの流れがより簡単に
-
ドキュメント用に構築された表現力豊かなクエリ言語
-
ドキュメント全体でのアドホッククエリと集計
ユースケース
-
カタログ
-
コンテンツ管理システム
-
ユーザープロファイル/パーソナライゼーション
-
モバイルアプリ
リアルタイムアプリケーションの台頭により、データへの高速なアクセスが可能なインメモリデータベースの人気が高まっています。インメモリデータベースは、データストレージ、管理、および操作を主にメインメモリに依存しています。インメモリは、メモリキャッシング用のオープンソースソフトウェアによって一般化されており、データをキャッシングすることで動的データベースを高速化し、外部データソースのクエリ回数を減らすことができます。
利点
-
ミリ秒未満のレイテンシー
-
毎秒数百万もの操作を実行
-
大幅なパフォーマンスの向上—ディスクベースと比較すると 3~4 倍以上
-
よりシンプルな命令セット
-
豊富なコマンドセットをサポート
-
あらゆる種類のデータベース (リレーショナルまたは非リレーショナル) や、ストレージサービスで使用可能
ユースケース
-
キャッシュ (ユースケースの 50% 以上はキャッシュに関連)
-
セッションストア
-
リーダーボード
-
地理空間アプリ (配車サービスなど)
-
パブ/サブ
-
リアルタイム分析
グラフデータベースは、セマンティッククエリにグラフ構造を使用する NoSQL データベースです。グラフは基本的にインデックスデータ構造です。特定のクエリの無関係なデータを読み込んだり、変更したりする必要はありません。グラフデータベースでは、データは、ノード、エッジ、およびプロパティの形式で保存されます。
利点
-
頻繁にスキーマを変更する機能
-
急増する膨大な量のデータを管理
-
リアルタイムのクエリ応答時間
-
大小を問わず、関連データをクエリするための優れたパフォーマンス
-
よりインテリジェントなデータアクティベーション要件に対応
-
各クエリの明示的なセマンティクス—非表示の前提がない
-
柔軟なオンラインスキーマ環境
ユースケース
-
不正検出
-
ソーシャルネットワーキング
-
レコメンデーションエンジン
-
知識グラフ
時系列データベース (TSDB) は、タイムスタンプ付きデータまたは時系列データ用に最適化されています。時系列データは、他のデータワークロードと大きく異なり、通常、データはイベントの発生順に記録され、追記専用で、クエリは常に一定の時間間隔で実行されます。
利点
-
長期にわたって追跡、モニタリング、集計する測定またはイベントに最適
-
時系列データを迅速に蓄積するための高いスケーラビリティ
-
データ保持ポリシー、連続クエリ、柔軟な時間集計など、多くの機能に対する堅牢なユーザービリティ
ユースケース:
-
DevOps
-
アプリケーションのモニタリング
-
産業用テレメトリ
-
IoT アプリケーション
台帳データベースは、透過的かつ変更ができず、かつ暗号で検証可能なトランザクションログを提供します。ログは信頼された中央機関によって所有されます。多くの組織は、アプリケーションデータの正確な履歴を維持するため、台帳のような機能を備えたアプリケーションを構築します。
利点
-
アプリケーションデータの正確な履歴を保持
-
変更不可で透過的
-
暗号で検証可能
-
高スケーラブル
ユースケース:
-
財務 - 貸方や借方などの台帳データを追跡
-
製造 - サプライチェーンシステム間でデータを照合して、製造履歴全体を追跡
-
保険 - 請求処理履歴を追跡
-
人事業務および給与 - 従業員に関する詳細な記録を追跡および維持
ワイドカラムデータベースは、永続的な多次元の Sparse マトリックスマッピングを表形式で使用する NoSQL データベースです。PB 規模、またはそれ以上の大量の収集データを保存できます。ワイドカラムデータベースでは、リレーショナルデータベースと同様に、テーブル、行、列が使用されます。ただし、リレーショナルデータベースとは異なり、その列の名前と形式は、同じテーブルの行ごとに異なる場合があります。
利点
-
大容量のデータに最適
-
非常に高速な書き込み速度
-
複雑なクエリを迅速に完了
-
データ圧縮が容易で、容量とコストを低減
-
既存のシステムとの統合が容易
ユースケース:
-
以下を目的とした大規模な業務アプリケーション:
- 設備の保守
- フリートの管理
- ルート最適化
-
データログ
-
地域別データ
データは飛躍的に増加している
データは扱うのが難しい代物です。データは急速に成長しており、ソースは新しくなり多様化が進んでいて、処理はますます難しくなっていきます。これらすべてを考慮した上で、企業が競争力を維持するために、ほぼリアルタイムでデータを取得して、保存し、分析するにはどうすればよいでしょうか。
データを保存、分析、利用するためのより良い方法とは?
データレイクでデータを利用できるようにする
データレイクアーキテクチャは、データウェアハウスと高度な分析 (機械学習を利用したソリューションを含む) を 1 つにして、データの価値をさらに引き出します。データレイクでは、すべてのデータを収集し、一元化された 1 つのリポジトリに保存することができます。これにより、最適なスケール、柔軟性、耐久性、可用性が生まれます。データレイクの最大の利点は、すべてのデータでの分析を高速化し、そのデータからインサイト (洞察) を取得するための時間を短縮できることです。

セキュアなデータレイクの構築
完全に生産性の高いデータレイクを手動で作成し実装するには、通常数か月におよぶ面倒で複雑な作業が必要になります。ストレージをセットアップして大量のデータを処理し、さまざまなソースからデータを収集して整理する必要があります。また、データをクリーニングして使用できるように準備し、複雑なセキュリティポリシーを設定および適用して、データを簡単に見つけられるようにする方法も必要です。幸いなことに、これらを実現するための、より高速で簡単なソリューションがあります。
AWS のデータレイクはここが違う
AWS Lake Formation を使えば、データレイクの作成プロセスを簡素化し、多くのステップを自動化することで、数か月ではなく数日で安全なデータレイクを設定できます。
-

より高速なセットアップ
データの移動、保存、カタログ化、クリーニングを加速し、自動化します。
-

より広範なセキュリティ
複数のサービスにわたりセキュリティポリシーを適用します。
-

より多くのインサイト (洞察)
アナリストやデータサイエンティストが、新しいインサイトを獲得し、それを管理できるようにします。
データレイクにより、多くの種類の分析が可能に
遡及的な分析とレポートから、リアルタイムの処理や予測分析まで、データレイクは理想的な選択です。
-

運用およびログの分析
-

データウェアハウジング
-
ビッグデータ処理
-

ストリーミングおよびリアルタイムの分析
-

予測分析
エンドユーザーがデータを表示し、可視化できるようにする
Amazon QuickSight は、ML Insights を含む高速なクラウド使用のインテリジェンスサービスです。自社用にインタラクティブなダッシュボードを構築しているか、アプリケーションやウェブサイトに分析を埋め込んでいるかにかかわらず、エンドユーザーはインサイト (洞察) を容易に取得できます。QuickSight は、ML Insights を含むクラウドベースの高度なインテリジェンスサービスで、QuickSight を使用することで、サービスやインフラストラクチャキャパシティーを管理する必要がなくなります。また、数万人のユーザーに簡単にスケールできるサーバーレスアーキテクチャを備えており、柔軟性の高いセッションごとの料金オプションにより、支払いは使用した分だけで済みます。
機械学習 (ML) でさらに多くのインサイト (洞察) を得る
機械学習 (ML) は、その潜在的な機能を完全に発揮する段階にはまだ到達していませんが、転換点に達しています。クラウドにより、機械学習はあらゆる規模のビジネスで利用できるようになりました。
すべてのユーザーを対象にした機械学習 (ML)
AWS は、最も多様で高度なレベルの一連の機械学習機能を備えており、あらゆるスキルレベルのデベロッパーやデータサイエンティスト (まったく未経験の方を含む) が、高度なモデルを作成することができます。現在、数万社のビジネスが AWS を使用して、強力で正確な予測や分析を作成しており、時間の経過とともによりスマートなインサイト (洞察) を得ています。
-
最も多様かつ高度なプラットフォーム
コンピュータビジョン、言語、推奨事項、予測にまたがる、人工知能を利用した高度なアプリケーションを簡単に構築できます。
-

経験は不要
Amazon SageMaker が、機械学習プロセスの各ステップにおける手間のかかる作業をなくし、モデルの構築、トレーニング、チューニング、デプロイを大幅に簡素化し高速化します。
-

絶対の自信を持てる
AWS なら、機械学習に最適化された最も包括的なクラウドプラットフォームを構築することができます。