Introducing
the Data Flywheel
The Data Flywheel is a comprehensive and additive approach for business and technology leaders to enable organizations to get the most value from their data.
Harnessing data can be a challenge, but you can innovate continuously, generate self-sustaining momentum, and get the most value from your data when you adopt a modern business framework.
Leave legacy
databases behind
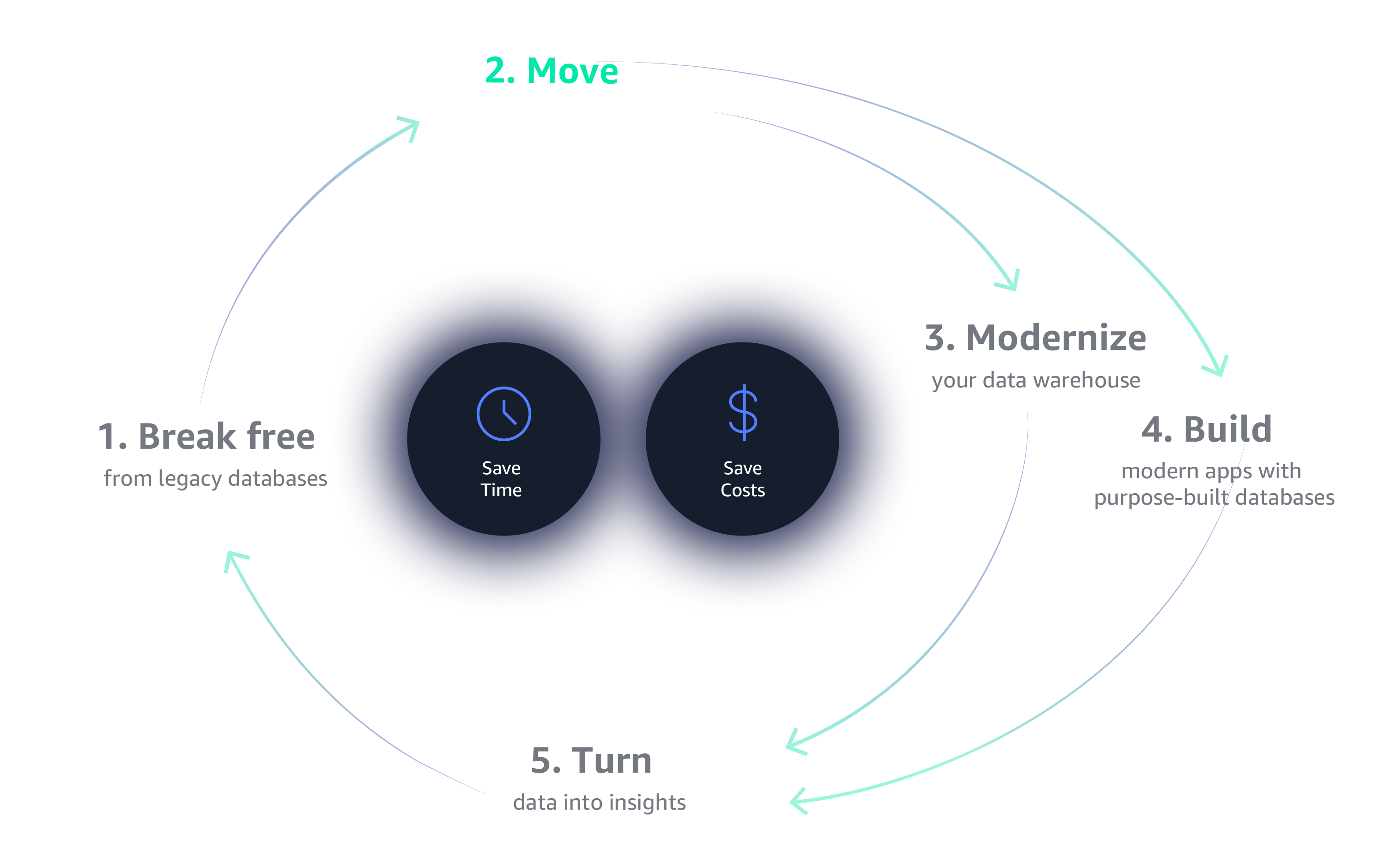
The first step to kick-starting your Data Flywheel is to break free of the constraints of legacy databases. Legacy databases are expensive, proprietary, lock you in, offer punitive licensing terms, and come with frequent audits. For these reasons and more, legacy databases simply can’t give you the scalability, flexibility, and cost-efficiency you need to build a data flywheel that can successfully achieve self-sustaining momentum.
Save time and costs with fully managed databases and analytics services
Managing your databases and analytics infrastructure can be tedious and time-consuming. Moving to fully managed services on AWS allows you to spend time innovating and building new apps, not managing infrastructure.
Go bigger and faster with modern data warehousing
A modern, cloud-based data warehousing strategy allows you to store, process, and analyze more data faster and more efficiently. It’s time to embrace more flexible architecture, like the data lake—a centralized repository that stores all your data and enables new types of analytics.
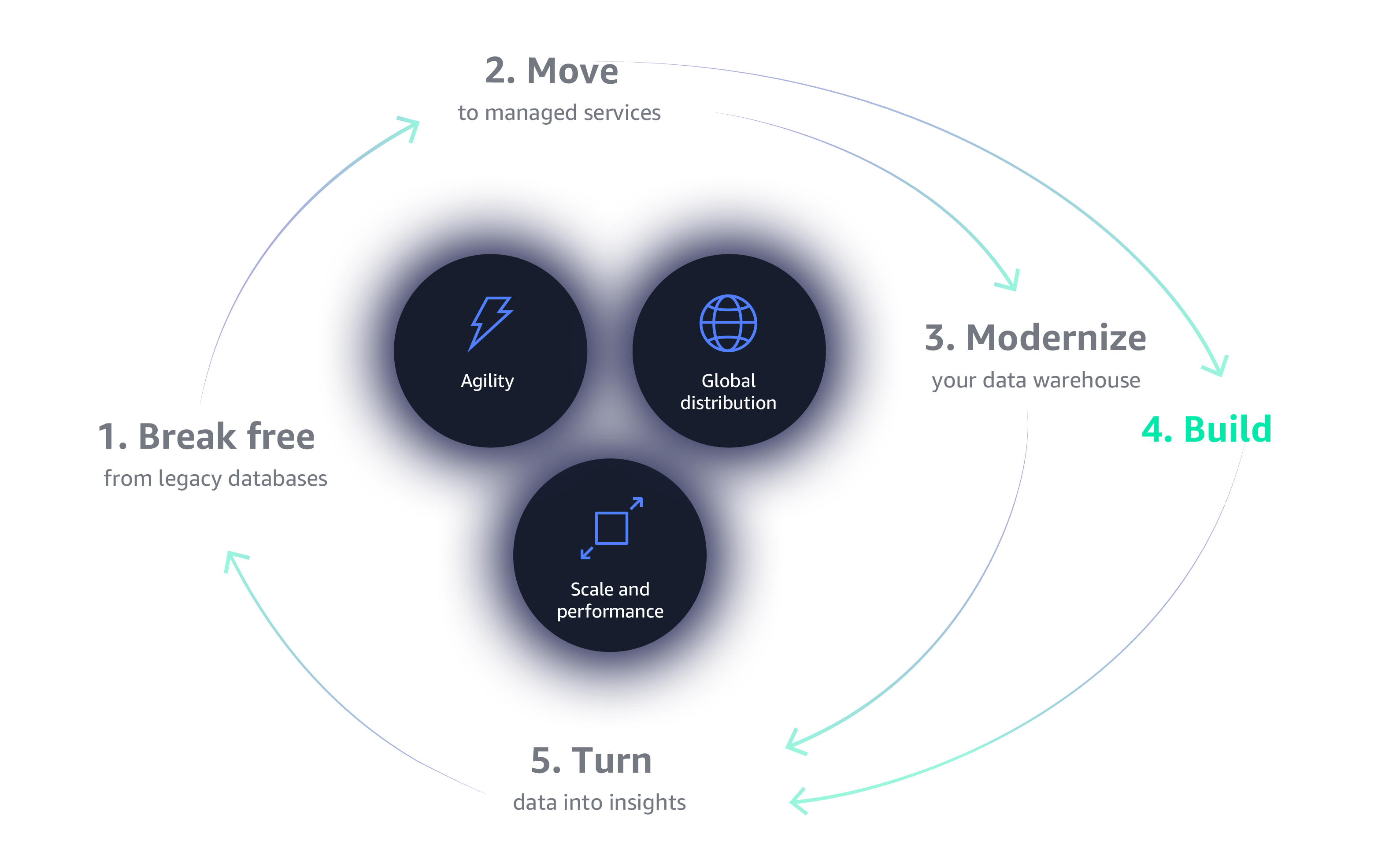
Build modern applications to increase momentum
Build modern applications with over 15 purpose-built databases. Give your teams the right tools for the right job to build high-performing, scalable, and available applications that will grow with your business.
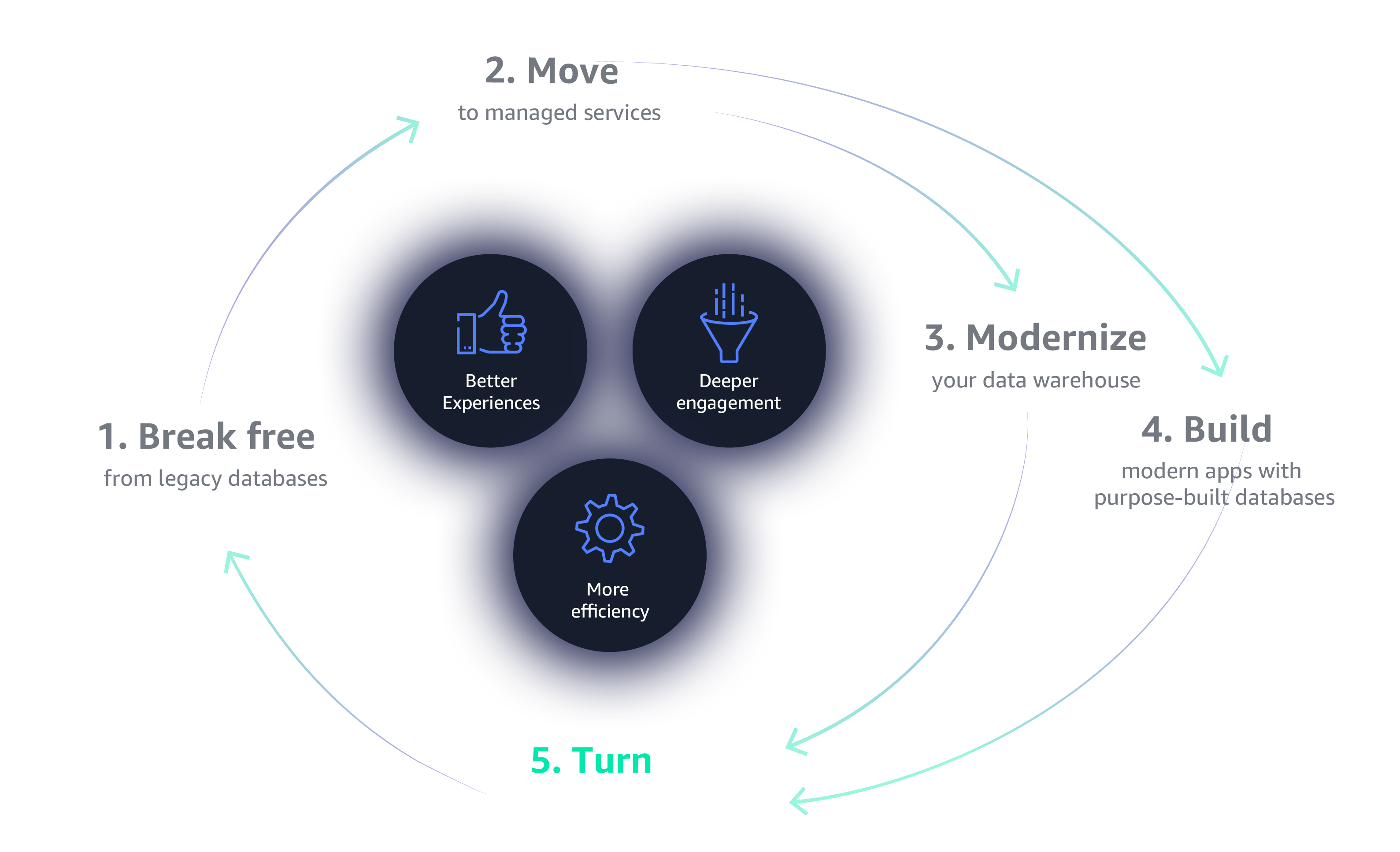
Get more value from your data
Your data is in the cloud—now make it work for you. Forget silos and incomplete analytics. Today’s businesses gather smart, accurate insights faster through data lakes, cloud analytics, and machine learning and empower end users to see and visualize their data from any device or application.
Create perpetual business momentum
According to thermodynamics, perpetual motion is impossible. But who said the laws of physics have to apply to business? When applied properly, data can generate self-sustaining, perpetually accelerating momentum for your organization.
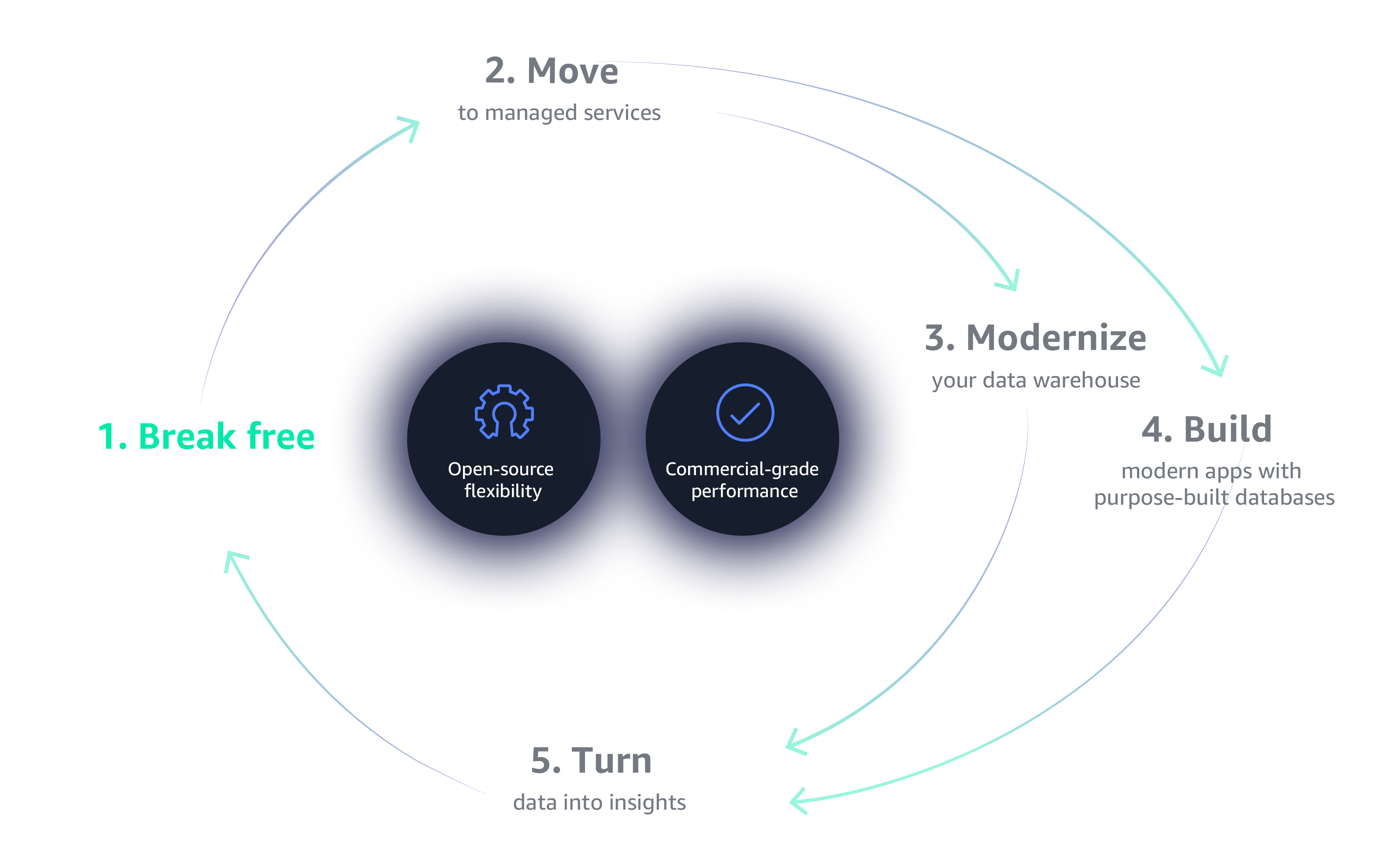
Why a flywheel?
The flywheel—as popularized by author Jim Collins—is a self-reinforcing loop made up of a few key initiatives that feed and are driven by each other to build long-term business momentum. In the early ‘90s, Jeff Bezos incubated his initial idea for Amazon.com using the Amazon flywheel, an economic engine that uses growth and scale to improve the customer experience through greater selection and lower cost.
Building a successful Data Flywheel
One of the most unique characteristics of the Data Flywheel is that no “one thing” powers it, and organizations that search for such a fundamentally basic solution will likely lose their way. The Data Flywheel moves by many components acting in concert, equating to a whole that’s greater than the sum of its parts. Organizations that take the time to develop each of these components, implementing the most relevant technologies and procedures at every phase, will prosper the most from the Data Flywheel.

Learn how to better store, analyze, and harness the power of your data.

Old-guard database providers
-

Very expensive
Legacy databases are expensive, and you end up paying more for license fees, maintenance, and support.
-

Proprietary
Innovation is confined, as you are limited to using proprietary database functions that limit innovation.
-

Lock-in
Contracts lock you in and may force you to buy things you don’t need.
-

Punitive licensing
Complex contractual licensing restricts flexibility and adds unpredictable costs.
-

Unexpected audits
Frequent audits can add unplanned costs to your deployments.
Customers are moving to open
source databases
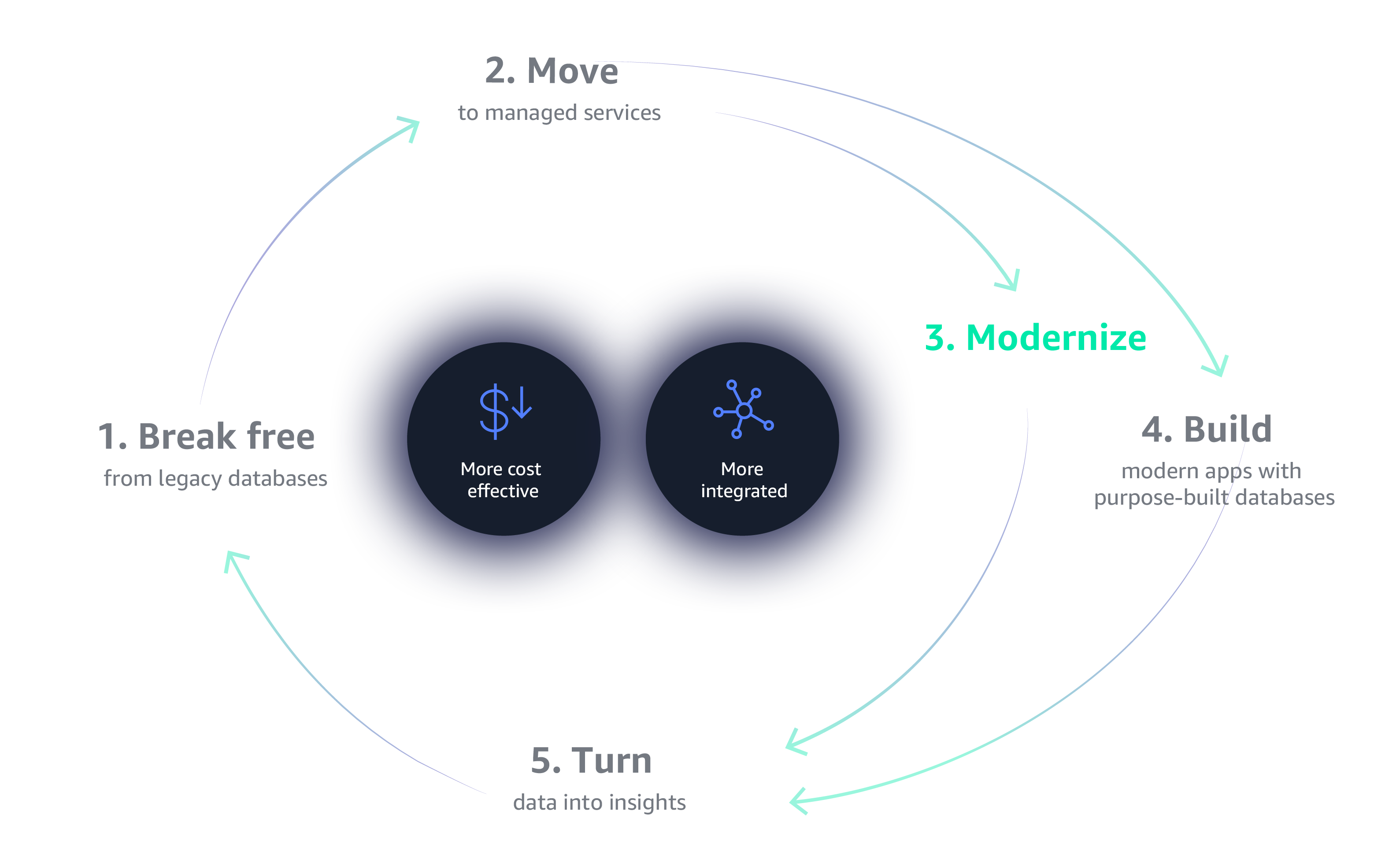
Because of the challenges with old-guard commercial databases, customers are moving as fast as they can to open source alternatives like MySQL, PostgreSQL, and MariaDB. However, they also want the performance and availability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases.
Discover the benefits of
cloud-based databases in
this O’Reilly eBook.
Get the best of both worlds
With AWS, you can get the performance and availability of commercial-grade databases with the simplicity and cost effectiveness of open source. Amazon Aurora is a relational database that’s compatible with MySQL and PostgreSQL and delivers substantially faster performance than standard open source databases—at 1/10 the cost of commercial-grade solutions. Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. And Amazon Redshift is both the fastest and most cost-efficient cloud data warehouse available.
Explore stories of customers that have moved
data and workloads to the cloud
Dow Jones frees up
funds for innovation
Dow Jones migrated their market data platform from Microsoft SQL Servers to Amazon Aurora, cutting costs by over 50%.
Amazon achieves
database freedom
By migrating nearly 7,500 Oracle databases to multiple AWS database services with 75 petabytes of data, Amazon reduced database costs by 60% and latency of customer-facing applications by 40%.
Why fully managed databases?
Database management can become a major burden to your business. In addition to hardware and software installation, you have to worry about database patching, backups, complicated cluster configuration for data replication and high availability, tedious capacity planning, and scaling clusters for compute and storage.
Amazon RDS boosts performance and saves time
Organizations often begin their move to managed services by migrating to Amazon Relational Database Service (RDS), a fully managed solution that can run your choice of database engines—including open source engines like MySQL and PostgreSQL, as well as Oracle and SQL Server. Amazon RDS improves database scale and performance and automates time-consuming administration tasks such as hardware provisioning, database setup, patching, and backups.
-

Easy to administer
Easily deploy and maintain hardware, OS, and database software; enjoy built-in monitoring.
-

Performant and scalable
Scale compute and storage with a few clicks and minimal downtime.
-

Available and durable
Get automatic Multi-AZ data replication and automated backup, snapshots, and failover.
-

Secure and compliant
Encrypt data at rest and in transit; take advantage of industry compliance and assurance programs.
Move all your databases to the cloud
To get even more benefits, move both your relational and non-relational databases to fully managed services in the cloud.
Learn how to overcome the
limitations of legacy data
architectures and get the most
from your data in this eBook.
Relational databases
Migrate from expensive Oracle and SQL Server databases to Amazon Aurora. Migrate from standard MySQL and PostgreSQL to Amazon RDS.
Non-relational databases
Move document- and key-value stores to Amazon DynamoDB, document databases like MongoDB to Amazon DocumentDB, and Cassandra databases to Amazon Keyspaces (for Apache Cassandra).
Why fully managed analytics?
Like their database counterparts, fully managed analytics services from AWS reduce costs and give you more time to dedicate to innovation. They also enable dynamic scalability, faster processing, easier visualizations, higher availability and resiliency, and stronger security.
-

Hadoop and Spark
Move on-premises Hadoop and Spark deployments to Amazon EMR for time and cost savings.
-

Operational analytics
Elasticsearch, Logstash, and Kibana (ELK) on-premises can move to Amazon Elasticsearch Service for time and cost savings.
-
Real-time analytics
Apache Kafka deployments can move to Amazon Managed Streaming for Apache Kafka (MSK), and Amazon Kinesis can prepare, load, and analyze data streams into data stores and analytics tools for immediate use.
Explore success stories of customers moving to fully managed database
and analytics services in the cloud
FanDuel achieves almost 100 percent uptime
FanDuel moves critical workloads to AWS using Amazon Aurora, achieving almost 100% uptime.
Autodesk gains new insights with real-time analytics
Using AWS, Autodesk attains deeper visibility into its log data, enabling faster problem detection and resolution.
Traditional data warehousing won’t get it done
A traditional, on-premises data warehousing strategy can’t meet the needs of the modern business.
-

Doesn’t scale
You’ll have to purchase and install larger, more powerful hardware every time you reach storage and compute capacity limits.
-

Too slow
Data needs to be moved to a separate analytics system before processing and analyzing—a process that’s too slow for real-time analytics.
-

Expensive
You’ll need to purchase from old-guard database providers, which are expensive, proprietary, and impose punitive licensing terms.
-

Rigid
It can’t suitably accommodate new data types generated by websites, mobile apps, and internet-connected devices.
-
Siloed
It doesn’t incorporate data that is being stored in data lakes or Hadoop.
-

Complex
Analytics are constrained to operational reporting on historical data by a smaller set of BI specialists.
Discover the most popular and fastest cloud data warehouse
Modernizing your data warehouse with Amazon Redshift gives you the performance, scale, and deep integration with your data lake to enable you to get the most value from your data.
See why now is the time to become an analytics-driven organization—and how a modern data warehouse and data lake solution can help you get there.
-

Most popular
Tens of thousands of customers use Amazon Redshift.
-
Integrated
Query petabytes of data across your data warehouse, data lake, and operational databases.
-

Fastest
Amazon Redshift is up to 3X faster than other cloud data warehouses.
-

Most cost-effective
Amazon Redshift is at least 50% less expensive than other cloud data warehouses.
Explore success stories of modern data warehousing
Nielsen builds cloud-native data reporting platform on AWS
By migrating to an AWS data lake solution, Nielsen grows from measuring 40,000 households to over 30 million households each day.
Equinox drives personalized customer experiences
AWS helps Equinox move to data lakes, enabling powerful analytics and more flexible data storage.
The rules for application design have changed
Modern applications place a new set of requirements on databases. Today’s apps need databases to scale from terabytes to petabytes of data, support millions of concurrent users, and deliver performance with millisecond and microsecond latency.
Requirements of applications today
- Users: 1 million +
- Data volume: TB–PB–EB
- Locality: Global
- Performance: Milliseconds–microseconds
- Request rate: Millions per second
- Access: Web, mobile, IoT, devices
- Scale: Up-down, out-in
- Economics: Pay for what you use
- Developer access: Instant API access
Store and retain all your data
-

Changing your strategy
The one-size-fits-all approach to databases is no longer enough.
-

Breaking down complex apps
To ensure proper architecture and scalability, you need to examine every application component.
-
Building highly distributed applications
Break down your complex applications into microservices.
Which databases are best for your workloads?
The best tool for a job usually differs by use case. That's why developers should use a multitude of purpose-built databases to build highly distributed applications.
Explore advantages and use cases for the most common application workloads below.

Need more detail? Download our introductory guide to finding the right database.
In relational database management systems (RDBMS), data is stored in a tabular form of columns and rows, and data is queried using the Structured Query Language (SQL). Each column of a table represents an attribute, each row in a table represents a record, and each field in a table represents a data value. Relational databases are so popular because 1) SQL is easy to learn and use without needing to know the underlying schema, and 2) database entries can be modified without specifying the entire body.
Advantages
-
Works well with structured data
-
Supports ACID transactions and complex joins
-
Built-in data integrity
-
Data accuracy and consistency
-
Limitless indexing
Use Cases
-
ERP
-
CRM
-
Finance
-
Transactions
-
Data warehousing
A key-value database uses a simple key-value method to store data as a collection of key-value pairs in which the key serves as a unique identifier. Both keys and values can be anything, ranging from simple objects to complex compound objects. They are great for applications that need instant scale to meet growing or unpredictable workloads.
Advantages
-
Simple data format accelerates write and read
-
Value can be anything, including JSON, flexible schemas, etc.
Use Cases
-
Real-time bidding
-
Shopping cart
-
Product catalog
-
Customer preferences
In document databases, data is stored in JSON-like documents, and JSON documents are first-class objects within the database. Documents are not a data type or a value; they are the key design point of the database. These databases make it easier for developers to store and query data by using the same document-model format developers use in their application code.
Advantages
-
Flexible, semi-structured, and hierarchical
-
Database evolves with application needs
-
Representation of hierarchical and semi-structured data is easy
-
Powerful indexing for fast querying
-
Documents map naturally to object-oriented programming
-
Easier flow of data to persistent layer
-
Expressive query languages built for documents
-
Ad-hoc queries and aggregations across documents
Use Cases
-
Catalogs
-
Content management systems
-
User profiles/personalization
-
Mobile apps
With the rise of real-time applications, in-memory databases that provide fast access to data are growing in popularity. In-memory databases predominantly rely on main memory for data storage, management, and manipulation. In-memory has been popularized by open-source software for memory caching, which can speed up dynamic databases by caching data to reduce the number of times an external data source must be queried.
Advantages
-
Sub-millisecond latency
-
Can perform millions of operations per second
-
Significant performance gains—3-4X or more when compared to disk-based alternatives
-
Simpler instruction set
-
Support for rich command set
-
Works with any type of database, relational or nonrelational, or even storage services
Use Cases
-
Caching (50%+ of use cases are caching)
-
Session store
-
Leaderboards
-
Geospatial apps (like ride-hailing services)
-
Pub/sub
-
Real-time analytics
Graph databases are NoSQL databases that use a graph structure for semantic queries. Graph is essentially an index data structure; it never needs to load or touch unrelated data for a given query. In graph databases, data is stored in the form of nodes, edges, and properties.
Advantages
-
Ability to make frequent schema changes
-
Can manage huge, exploding volume of data
-
Real-time query response time
-
Superior performance for querying related data, big or small
-
Meets more intelligent data activation requirements
-
Explicit semantics for each query—no hidden assumptions
-
Flexible online schema environment
Use Cases
-
Fraud detection
-
Social networking
-
Recommendation engines
-
Knowledge graphs
Time series databases (TSDBs) are optimized for time-stamped or time series data. Time series data is very different from other data workloads in that it typically arrives in time order form, the data is append-only, and queries are always over a time interval.
Advantages
-
Ideal for measurements or events that are tracked, monitored, and aggregated over time
-
High scalability for quickly accumulating time series data
-
Robust usability for many functions, such as data retention policies, continuous queries, and flexible-time aggregations
Use Cases:
-
DevOps
-
Application monitoring
-
Industrial telemetry
-
IoT applications
Ledger databases provide a transparent, immutable, and cryptographically verifiable transaction log owned by a central, trusted authority. Many organizations build applications with ledger-like functionality because they want to maintain an accurate history of their applications’ data.
Advantages
-
Maintains accurate history of application data
-
Immutable and transparent
-
Cryptographically verifiable
-
Highly scalable
Use Cases:
-
Finance - Keep track of ledger data such as credits and debits
-
Manufacturing - Reconcile data between supply chain systems to track full manufacturing history
-
Insurance - Track claim transaction histories
-
HR and Payroll - Track and maintain a record of employee details
Wide column databases are NoSQL databases that use persistent, multi-dimensional, sparse matrix mapping in a tabular format. They can store large volumes of collected data—up to and above the PB scale. Like relational databases, wide column databases use tables, rows, and columns. Unlike relational databases, however, the names and format of their columns can vary from row to row in the same table.
Advantages
-
Good for large data volumes
-
Very fast write speeds
-
Complex queries return quickly
-
Data compresses easily, saving space and costs
-
Integrates well with existing systems
Use Cases:
-
High-scale industrial applications for:
- Equipment maintenance
- Fleet management
- Route optimization
-
Data logs
-
Geographic data
Check out stories of cloud database success
Airbnb travels by cloud
Airbnb moved its main MySQL database to the cloud, discovering greater flexibility and responsiveness.
Duolingo learns fluent database
With its 31-million-item cloud databases, Duolingo achieves 24,000 reads per second.
Data is growing exponentially
Data is a difficult beast to tame. It’s growing exponentially, coming in from new sources, becoming more diverse, and is more and more difficult to process. With all that in mind, how can your business possibly capture, store, and analyze data fast enough to remain competitive?
Learn how to better store, analyze, and harness the power of your data.
Put your data to work with data lakes
Data lake architectures bring data warehousing and advanced analytics (including solutions powered by machine learning) together to help you derive more value from your data. Data lakes allow you to collect and store any data in one centralized repository. This provides optimum scale, flexibility, durability, and availability. But best of all, data lakes make performing analytics on all your data faster and reduce the time it takes to get insights out of that data.

Building a secure data lake is challenging
Manually creating and implementing a fully productive data lake generally requires months of tedious, complicated work. You’ll need to set up storage to handle massive amounts of data, collect and organize data from various sources, clean the data to prepare it for use, configure and enforce complex security policies, and find ways to make the data easy to locate. Thankfully, there’s a faster, easier solution.
Data lakes on AWS are different
AWS Lake Formation simplifies the lake creation process and automates many steps, enabling you to set up a secure data lake in days, not months.
-

Faster setup
Accelerate and automate the moving, storing, cataloging, and cleaning of your data.
-

Broader security
Enforce security policies across multiple services.
-

More insights
Empower your analysts and data scientists to gain and manage new insights.
Data lakes enable many types of analytics
From retrospective analysis and reporting to here-and-now real-time processing, to predictive analytics, data lakes are the ideal choice.
-

Operational and log analytics
-

Data warehousing
-
Big data processing
-

Streaming and real-time analytics
-

Predictive analytics
Enable end-users to see and visualize your data
Easily deliver insights to end-users, whether you are building interactive dashboards for your organization, or embedding analytics in your applications or websites. Amazon QuickSight is a fast, cloud-powered business intelligence service that includes ML insights. QuickSight eliminates the need to manage servers or infrastructure capacity. It has a serverless architecture that lets you easily scale to tens of thousands of users, and with its flexible pay-per-session pricing option, you pay for only what you use.
Get more insights with machine learning
While machine learning has yet to reach its full potential, we have hit a tipping point—the cloud has made machine learning available to businesses of every size.
Machine learning for all
With the broadest and deepest set of machine learning capabilities, AWS enables developers and data scientists of all skill levels—even those with no prior experience—to create sophisticated models. Tens of thousands of businesses use AWS today to generate powerfully accurate predictions and analytics that reveal increasingly smarter insights over time.
-
Broadest and deepest capabilities
Easily build sophisticated AI-driven applications spanning computer vision, language, recommendations, and forecasting?
-

No experience necessary
Amazon SageMaker removes the heavy lifting from each step of the machine learning process, making it much easier to build, train, tune, and deploy models.
-

Total confidence
Get peace of mind by building on AWS, the most comprehensive cloud platform optimized for machine learning.
Explore analytics use cases brought to life by real customers
INVISTA innovates faster with AWS
By moving to AWS data lakes, INVISTA reduces data retrieval time from months to minutes and extends data access to more users.
Zappos creates breakthrough customer experiences
Zappos uses AWS analytics and machine learning services to deliver personalized experiences that drive engagement and reduce returns.
Woot cheers for 90% lower operating costs
“By using Amazon QuickSight, anyone can build graphs and other visualizations just by dragging and dropping, with no SQL knowledge needed.”