Apresentação
do data flywheel
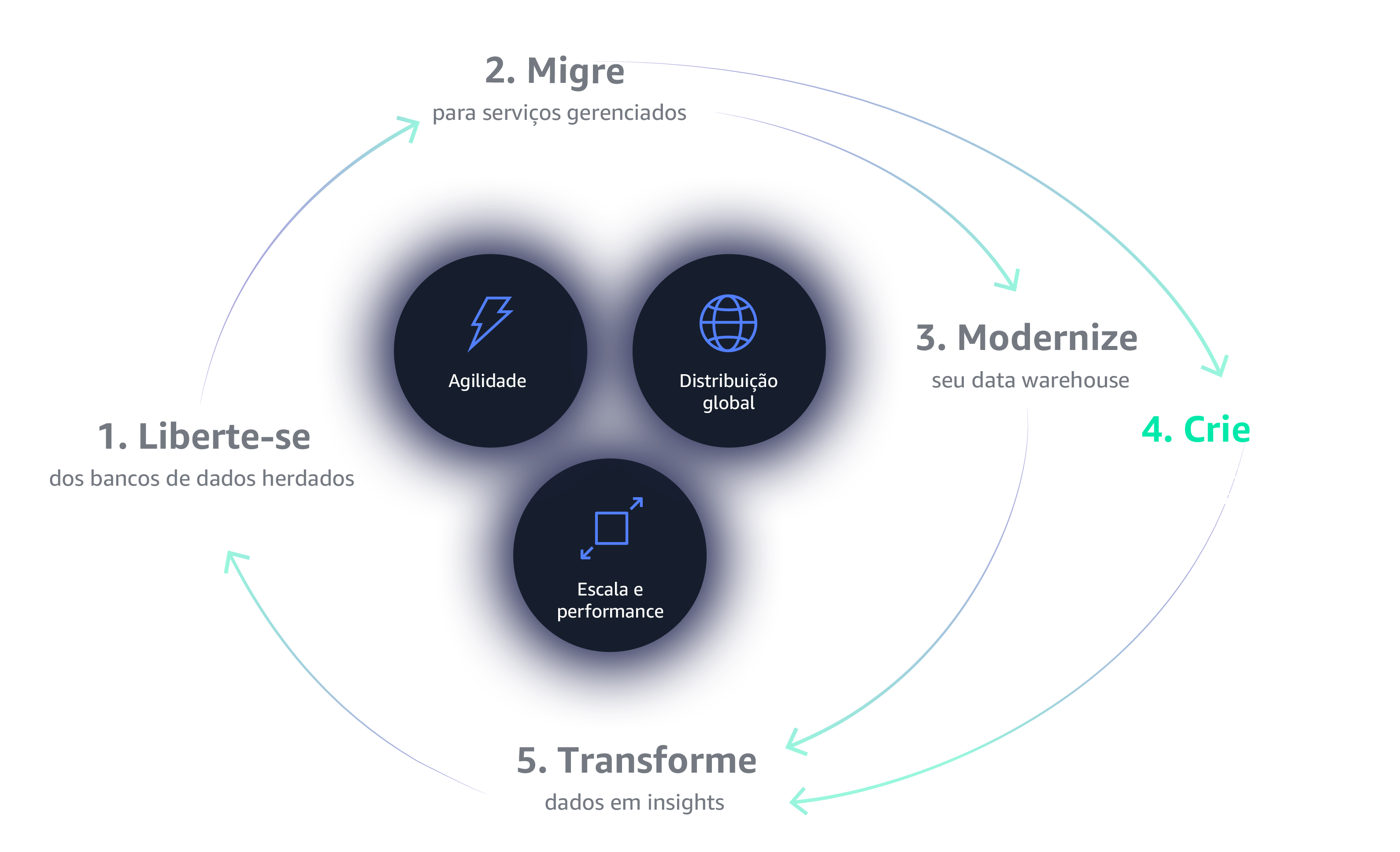
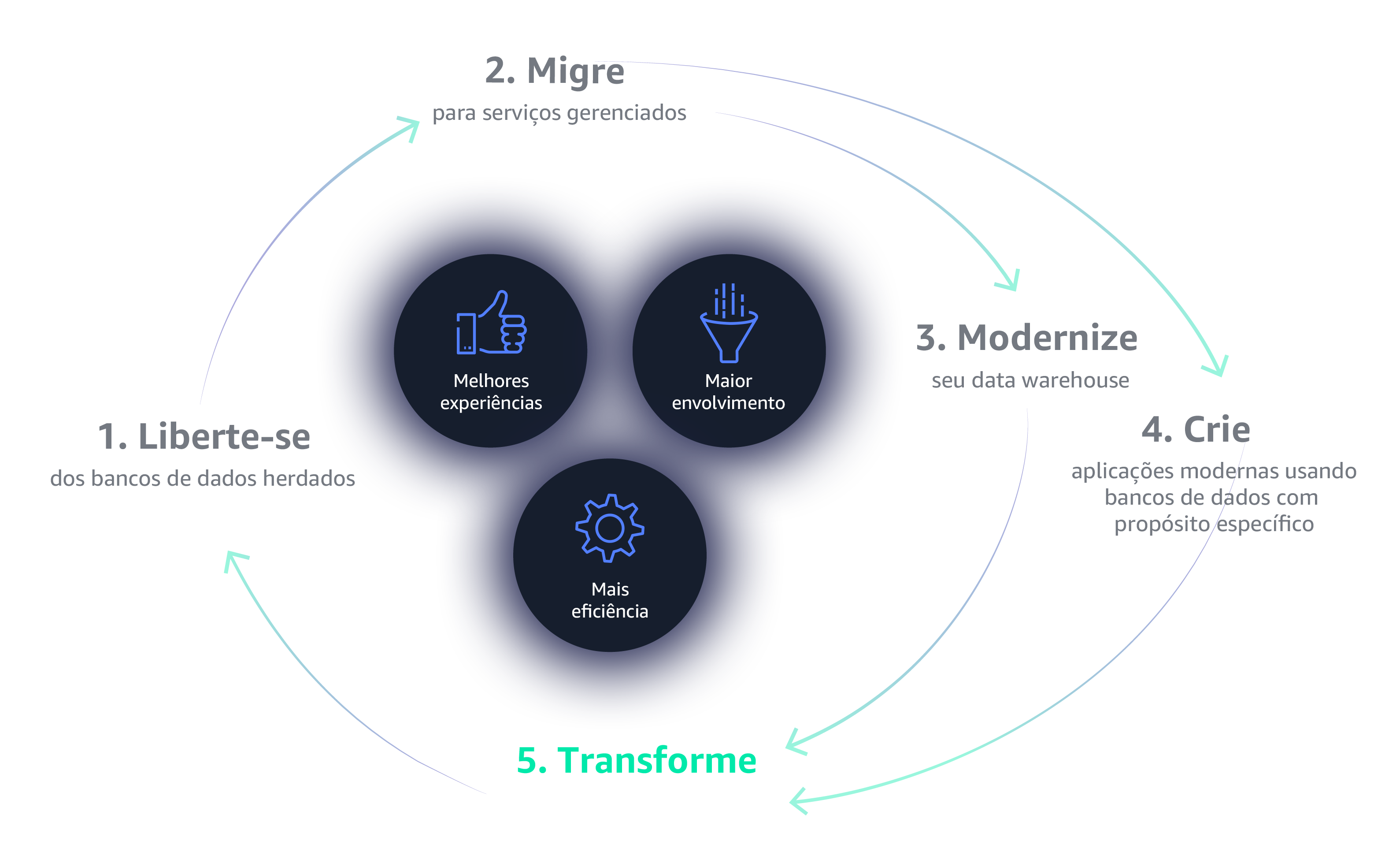
O data flywheel é uma abordagem abrangente e atrativa para líderes de negócios e tecnologia, projetada para permitir que as organizações obtenham o máximo valor dos seus dados.
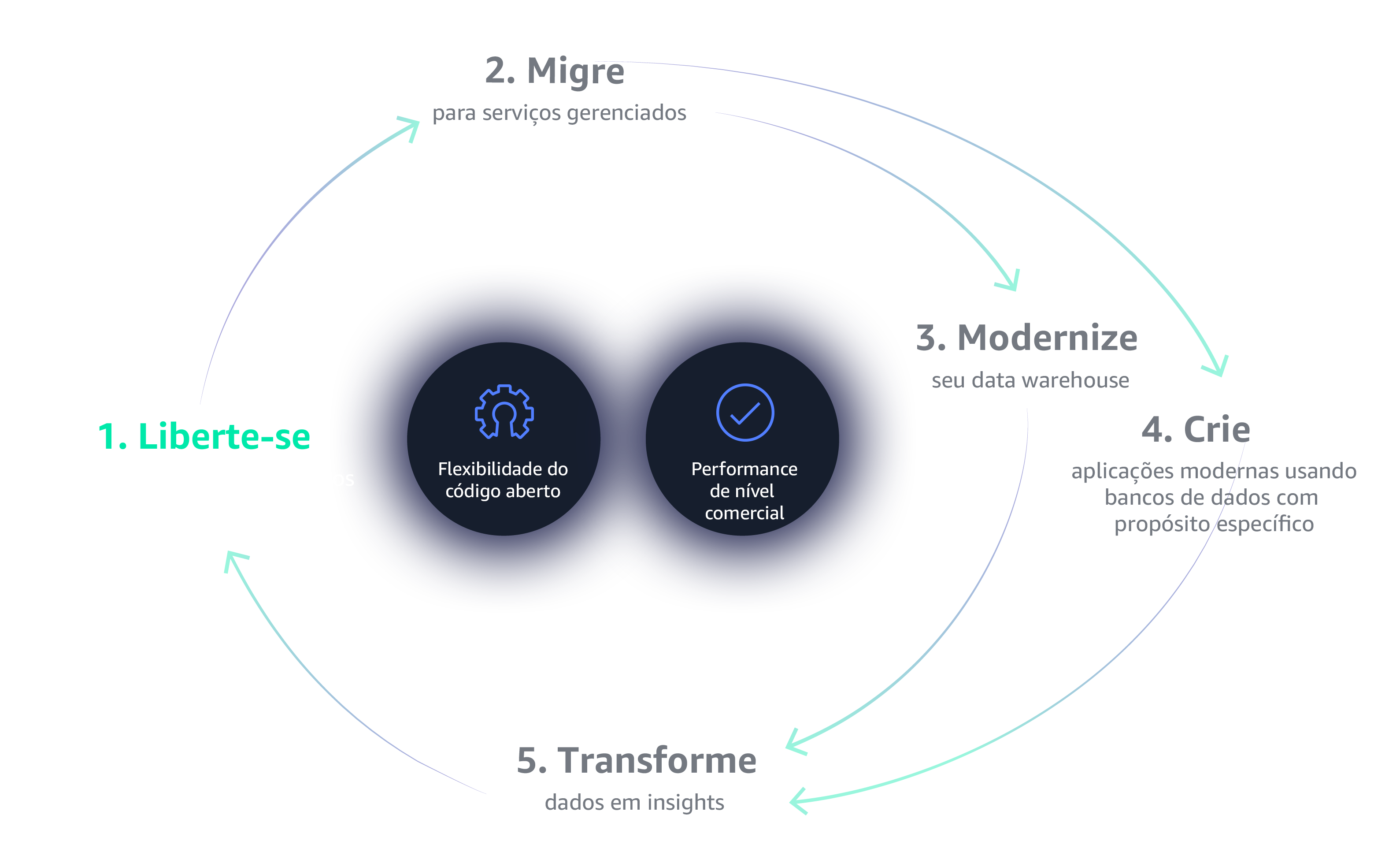
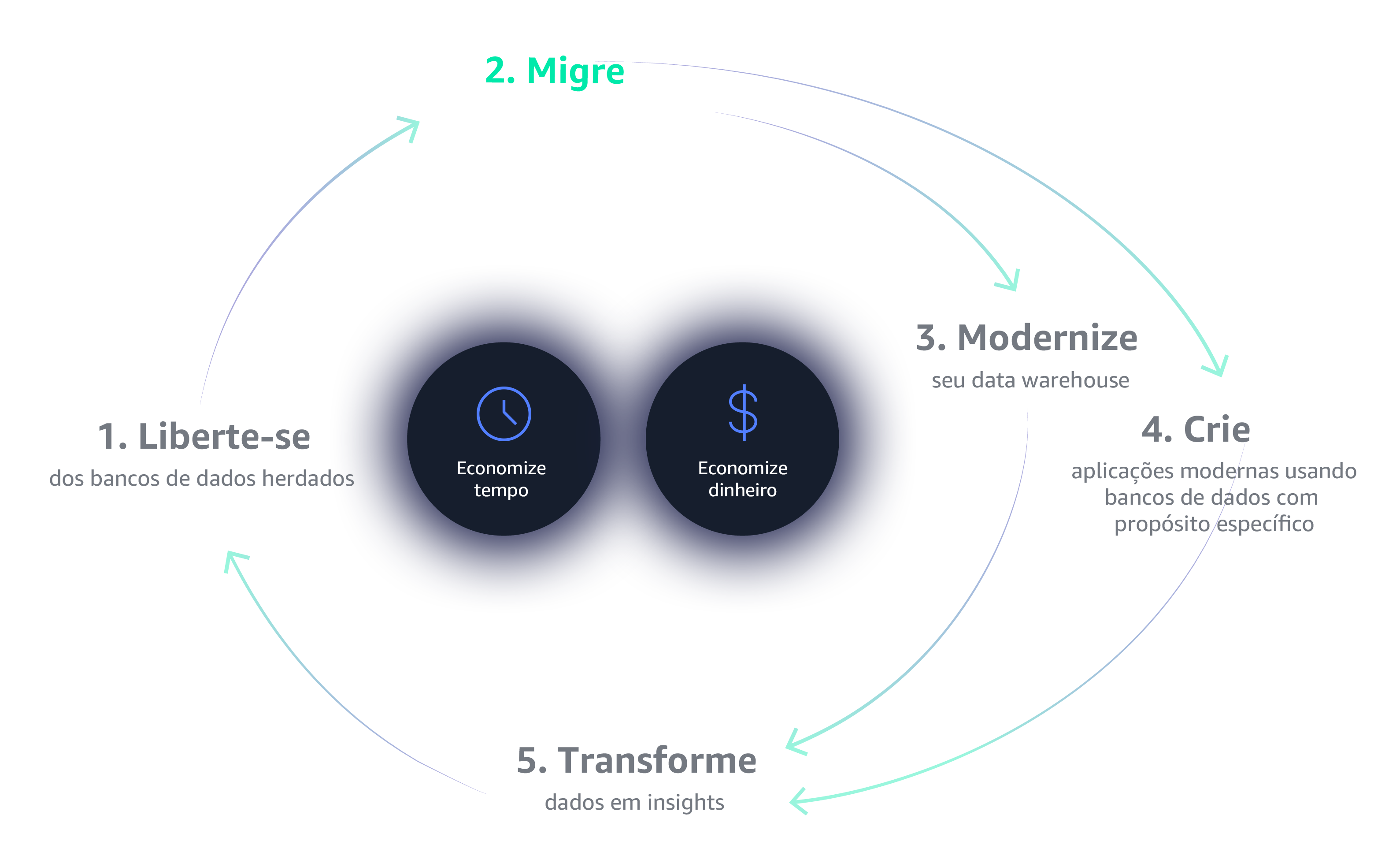
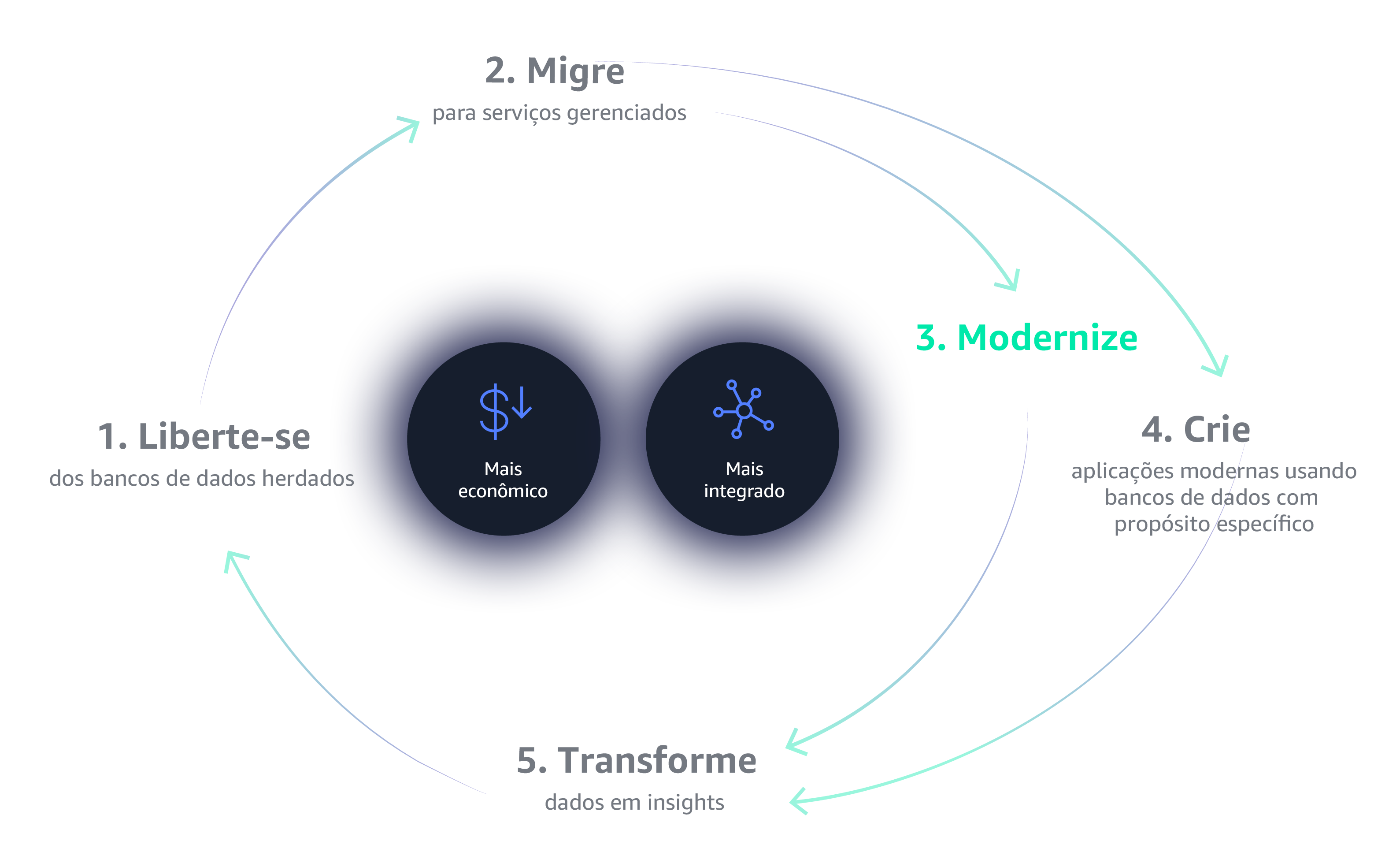
Deixe os bancos de dados
legados para trás
A primeira etapa para começar a usar o Data Flywheel é libertar-se das restrições de bancos de dados legados. Os bancos de dados legados são caros, proprietários, confinantes, oferecem termos de licenciamento punitivos e requerem auditorias frequentes. Por esses motivos e muito mais, os bancos de dados legados simplesmente não fornecem a escalabilidade, a flexibilidade e o custo/benefício de que você precisa para criar um volante de dados que possa obter um impulso autossustentável com êxito.
Economize tempo e custos com serviços de bancos de dados e análise totalmente gerenciados
O gerenciamento da infraestrutura de bancos de dados e análise pode ser tedioso e demorado. A mudança para os serviços totalmente gerenciados da AWS permite que você gaste seu tempo inovando e criando novas aplicações, não gerenciando a infraestrutura.
Aumente e agilize sua empresa com o data warehousing
Uma estratégia de data warehousing moderna e baseada em nuvem permite armazenar, processar e analisar mais dados com mais rapidez e eficiência. Está na hora de adotar uma arquitetura mais flexível, como o data lake, um repositório centralizado que armazena todos os seus dados e permite novos tipos de análise.
Crie aplicações modernas para aumentar o impulso
Crie aplicações modernas com bancos de dados criados para mais de 15 casos de usos específicos. Forneça as ferramentas certas para o trabalho certo para suas equipes criarem aplicações de alto desempenho e escaláveis, que vão crescer junto com o seu negócio.
Obtenha mais valor de seus dados
Seus dados estão na nuvem, agora faça com que eles trabalhem para você. Empresas modernas coletam dados precisos e obtêm insights mais rapidamente por meio de data lakes, análises em nuvem e machine learning, e capacitam seus usuários finais para ver e visualizar seus dados em qualquer dispositivo ou aplicativo.
Crie ímpeto empresarial contínuo
De acordo com a termodinâmica, o movimento perpétuo é impossível. Mas quem disse que as leis da física se aplicam às empresas? Quando usados adequadamente, os dados podem gerar um impulso de aceleração autossustentável e perpétuo para sua organização.
Por que um volante de inércia?
O conceito de flywheel, ou volante de inércia, como popularizado pelo escritor Jim Collins, é um ciclo de retroalimentação composto por algumas iniciativas importantes, que nutrem e impulsionam umas às outras para criar um ímpeto empresarial duradouro. No início da década de 1990, Jeff Bezos incubou sua ideia inicial da Amazon.com usando o Amazon Flywheel, um mecanismo econômico que usa crescimento e escala para melhorar a experiência do cliente com mais seleções e custo reduzido.
Crie um data flywheel de sucesso
Um dos diferenciais do data flywheel é que não existe um aspecto só que o habilita, e é provável que as organizações que buscam essa solução fundamentalmente básica se percam no caminho. O data flywheel se movimenta por muitos componentes que funcionam em harmonia, fazendo com que o todo seja maior do que a soma de suas partes. As organizações que dedicam tempo para desenvolver cada um desses componentes, implantando as tecnologias e os procedimentos mais relevantes em cada fase, vão aproveitar ao máximo o data flywheel.

Bancos de dados antiquados
-

Muito caros
Os bancos de dados legados são caros, e você acaba pagando mais por taxas de licença, manutenção e suporte.
-

Proprietários
A inovação é confinada, uma vez que você é limitado a usar funções de bancos de dados proprietários que limitam a inovação
-

Confinantes
Os contratos limitam você e podem forçá-lo a comprar coisas de que não precisa.
-

Licenciamento punitivo
O licenciamento contratual complexo restringe a flexibilidade e adiciona custos imprevisíveis.
-

Auditorias inesperadas
As auditorias frequentes podem adicionar custos não planejados às suas implantações.
Os clientes estão mudando para
bancos de dados de código aberto
Devido aos desafios com os bancos de dados comerciais antiquados, os clientes estão mudando o mais rápido possível para alternativas de código aberto, como o MySQL, o PostgreSQL e o MariaDB. Contudo, eles também querem o desempenho e a disponibilidade dos bancos de dados comerciais de ponta com a simplicidade e a economia dos bancos de dados de código aberto.
Tenha o melhor dos dois mundos
Com a AWS, você pode obter o desempenho e a disponibilidade de bancos de dados de categoria comercial com a simplicidade e a relação custo/benefício do código aberto. O Amazon Aurora é um banco de dados relacional compatível com MySQL e PostgreSQL e oferece um desempenho consideravelmente mais rápido do que os bancos de dados de código aberto padrão, por um décimo do custo das soluções de nível comercial. O Amazon DynamoDB é um banco de dados de documentos e chave/valor que fornece desempenho inferior a 10 milissegundos em qualquer escala. E o Amazon Redshift é o data warehouse de nuvem mais rápido e mais econômico disponível.
Explore histórias de clientes que mudaram
dados e workloads para a nuvem
A Dow Jones libera
fundos para inovação
A Dow Jones migrou sua plataforma de dados de mercado do Microsoft SQL Server para o Amazon Aurora, reduzindo os custos em mais de 50%.
A Amazon obtém a
liberdade de bancos de dados
Ao migrar quase 7.500 bancos de dados Oracle para vários serviços de banco de dados da AWS com 75 petabytes de dados, a Amazon reduziu os custos em 60% e a latência dos aplicativos voltados para o cliente em 40%.
Por que bancos de dados totalmente gerenciados?
O gerenciamento do banco de dados pode se tornar um peso para a empresa. Além da instalação de hardware e de software, você precisa se preocupar com a aplicação de patches e os backups de banco de dados, a configuração complicada de clusters para replicação de dados e alta disponibilidade, o planejamento tedioso da capacidade e a escalabilidade de clusters para computação e armazenamento.
O Amazon RDS aumenta o desempenho e economiza tempo
Normalmente, as organizações começam a mudar para serviços gerenciados migrando para o Amazon Relational Database Service (RDS), uma solução totalmente gerenciada que pode executar sua escolha de mecanismos de banco de dados, incluindo mecanismos de código aberto, como o MySQL e o PostgreSQL, bem como o Oracle e o SQL Server. O Amazon RDS melhora a escala e o desempenho do banco de dados e automatiza tarefas administrativas demoradas, como o provisionamento de hardware, a configuração do banco de dados, a aplicação de patches e os backups.
-

Fácil de administrar
Fácil de implantar e de manter o hardware, o SO e o software de banco de dados. Desfrute do monitoramento incorporado.
-

Eficiente e escalável
Dimensione a computação e o armazenamento com alguns cliques e tempo mínimo de inatividade.
-

Disponível e durável
Obtenha replicação de dados Multi-AZ automática e backup, snapshots e failover automatizados.
-

Seguro e em conformidade
Criptografe os dados em repouso e em trânsito. Tire proveito dos programas de conformidade e de garantia do setor.
Mude todos os seus bancos de dados para a nuvem
Para ter ainda mais benefícios, mude seus bancos de dados relacionais e não relacionais para serviços totalmente gerenciados na nuvem.

Saiba como superar as
limitações de arquiteturas de dados legados
e obter o máximo
dos seus dados neste e-book.
Bancos de dados relacionais
Migre de bancos de dados Oracle e SQL Server caros para o Amazon Aurora. Migre do MySQL e do PostgreSQL padrão para o Amazon RDS.
Bancos de dados não relacionais
Mude o armazenamento de documentos e de chave/valor para o Amazon DynamoDB, os bancos de dados de documentos como o MongoDB para o Amazon DocumentDB e os bancos de dados Cassandra para o Amazon Keyspaces (para Apache Cassandra).
Por que análise totalmente gerenciada?
Os serviços de análise da AWS reduzem os custos e liberam mais tempo para que você se dedique à inovação. Eles também permitem escalabilidade dinâmica, processamento mais rápido, visualizações mais fáceis, disponibilidade e resiliência mais altas e segurança mais forte.
-

Hadoop e Spark
Mude as implantações on-premise do Hadoop e do Spark para o Amazon EMR para obter economias de tempo e de custos.
-

Análise operacional
Elasticsearch, Logstash e Kibana (ELK) na infraestrutura on-premise podem ser migrados para o Amazon Elasticsearch Service para economia de tempo e dinheiro.
-
Análise em tempo real
As implantações do Apache Kafka podem mudar para o Amazon Managed Streaming for Apache Kafka (MSK), e o Amazon Kinesis pode preparar, carregar e analisar stream de dados para armazenamentos de dados e ferramentas de análise para uso imediato.
Explore histórias de sucesso de clientes que mudaram para serviços de
banco de dados e análise totalmente gerenciados na nuvem
A FanDuel obtém quase 100% de tempo de atividade
A FanDuel mudou cargas de trabalho críticas para a AWS usando o Amazon Aurora, obtendo quase 100% de tempo de atividade.
A Autodesk obtém novos insights com a análise em tempo real
Usando a AWS, a Autodesk conquista visibilidade mais profunda de seus dados de log, o que permite detecção e resolução de problemas com mais rapidez.
Data warehousing tradicional
Uma estratégia tradicional e on-premise de data warehousing não atende as necessidades da empresa moderna.
-

Não é escalável
Você precisa comprar e instalar hardware maior e mais poderoso toda vez que o limite do armazenamento e da capacidade computacional são atingidos.
-

Muito lento
Os dados precisam ser movidos para um sistema de análise separado para processamento e análise, um processo que é muito lento para análise em tempo real.
-

Caro
Você precisa comprar de provedores de bancos de dados antiquados, que são caros, proprietários e impõem termos de licenciamento punitivos.
-

Rígido
Ele não pode acomodar adequadamente novos tipos de dados gerados por sites, aplicativos móveis e dispositivos conectados à Internet.
-
Em silos
Não incorpora dados que estão sendo armazenados em data lakes ou no Hadoop.
-

Complexo
A análise é limitada a relatórios operacionais sobre dados históricos por um conjunto menor de especialistas de business intelligence.
Descubra o data warehouse de nuvem mais popular e mais rápido
A modernização de seu data warehouse com o Amazon Redshift fornece desempenho, escala e integração profunda com seu data lake para permitir que você obtenha o valor máximo dos seus dados.
Veja por que agora é o momento de se tornar uma empresa orientada a análises, e como um data warehouse moderno e uma solução de data lake podem ajudar você a chegar lá.
-

Mais popular
Dezenas de milhares de clientes usam o Amazon Redshift.
-
Integrado
Consulte petabytes de dados em seu data warehouse, data lake e bancos de dados operacionais.
-

Mais rápido
O Amazon Redshift é três vezes mais rápido do que outros data warehouses de nuvem.
-

Mais econômico
O Amazon Redshift é pelo menos 50% mais barato do que outros data warehouses de nuvem.
Explore histórias de sucesso de data warehousing
A Neilsen baseia a plataforma de criação de relatórios de dados nativos da nuvem na AWS
Com a migração para uma solução de data lake da AWS, a Nielsen aumenta a medição de 40.000 residências para mais de 30 milhões de residências a cada dia.
A Equinox proporciona experiências personalizadas a seus clientes
A AWS ajuda a Equinox a mudar para data lakes, permitindo análises eficientes e um armazenamento de dados mais flexível.
As regras mudaram para o design de aplicações
As aplicações modernas estabelecem um novo conjunto de requisitos para bancos de dados. As aplicações atuais precisam de bancos de dados para escalar de terabytes para petabytes de dados, oferecer suporte a milhões de usuários simultâneos e fornecer desempenho com latência de milissegundos e microssegundos.
Requisitos das aplicações atuais
- Usuários: mais de 1 milhão
- Volume de dados: TB, PB, EB
- Localidade: global
- Desempenho: milissegundos a microssegundos
- Taxa de solicitações: milhões por segundo
- Acesso: Web, móvel, IoT, dispositivos
- Escala: vertical, horizontal
- Economia: pagar pelo que você usa
- Acesso de desenvolvedores: acesso instantâneo à API
Armazene e retenha todos os seus dados
-

Mudar sua estratégia
A abordagem única para todos os casos de bancos de dados não é mais suficiente.
-

Segmentar aplicações complexas
Para garantir a arquitetura e a escalabilidade adequadas, você precisa examinar cada componente da aplicação.
-
Criar aplicações altamente distribuídas
Divida suas aplicações complexas em microsserviços.
Quais bancos de dados são melhores para os seus workloads?
A melhor ferramenta para um trabalho geralmente é diferente, dependendo do caso de uso. É por isso que os desenvolvedores devem usar vários bancos de dados de uso específico para criar aplicações altamente distribuídas.
Explore a seguir as vantagens e os casos de uso de workloads de aplicações mais comuns.
Em sistemas de gerenciamento de bancos de dados relacionais (RDBMS), os dados são armazenados em uma forma tabular de colunas e linhas, e são consultados usando o Structured Query Language (SQL). Cada coluna de uma tabela representa um atributo, cada linha em uma tabela representa um registro e cada campo em uma tabela representa um valor de dados. Os bancos de dados relacionais são tão populares porque 1) o SQL é fácil de aprender e usar, sem a necessidade de conhecer o esquema subjacente, e 2) as entradas do banco de dados podem ser modificadas sem especificar o corpo inteiro.
Vantagens
-
Funciona bem com dados estruturados
-
É compatível com transações ACID e junções complexas
-
Integridade de dados incorporada
-
Precisão e consistência de dados
-
Indexação ilimitada
Casos de uso
-
ERP
-
CRM
-
Finanças
-
Transações
-
Data warehousing
Um banco de dados de chave-valor usa um método de chave-valor simples para armazenar os dados como uma coleção de pares de chave/valor na qual a chave funciona com um identificador exclusivo. As chaves e os valores podem ser qualquer coisa, de objetos simples a objetos compostos complexos. Elas são ótimas para aplicações que precisam de escala instantânea para atender a workloads crescentes ou imprevisíveis.
Vantagens
-
O formato simples de dados acelera a leitura e a gravação
-
O valor pode ser qualquer coisa, incluindo JSON, esquemas flexíveis etc.
Casos de uso
-
Lances em tempo real
-
Carrinho de compras
-
Catálogo de produtos
-
Preferências do cliente
Em bancos de dados de documentos, os dados são armazenados em documentos do tipo JSON, e documentos JSON são objetos de primeira classe no banco de dados. Documentos não são um tipo de dados ou um valor; eles são o principal ponto de design do banco de dados. Esses bancos de dados facilitam que os desenvolvedores armazenem e consultem dados usando o mesmo formato de modelo de documento que os desenvolvedores usam no código do aplicativo.
Vantagens
-
Flexível, semiestruturado e hierárquico
-
O banco de dados evolui com as necessidades do aplicativo
-
A representação de dados hierárquicos e semiestruturados é fácil
-
Indexação poderosa para uma consulta rápida
-
Os documentos são mapeados naturalmente para a programação orientada a objeto
-
Fluxo de dados fácil para camada persistente
-
Linguagens de consulta expressivas criadas para documentos
-
Consultas ad-hoc e agregações nos documentos
Casos de uso
-
Catálogos
-
Sistemas de gerenciamento de conteúdo
-
Perfis/personalização de usuários
-
Aplicativos móveis
Com o aumento de aplicações em tempo real, está crescendo a popularidade dos bancos de dados em memória que fornecem acesso rápido aos dados. Os bancos de dados em memória dependem principalmente da memória principal para armazenamento, gerenciamento e manipulação de dados. O uso da memória foi popularizado pelo software de código aberto para cache de memória, o que pode acelerar os bancos de dados dinâmicos armazenando os dados em cache para reduzir o número de vezes que uma fonte de dados externa deve ser consultada.
Vantagens
-
Latência abaixo de um milissegundo
-
Pode realizar milhões de operações por segundo
-
Ganhos significativos de desempenho: 3-4x ou mais quando comparado com alternativas baseadas em disco
-
Conjunto mais simples de instruções
-
Suporte a um amplo conjunto de comandos
-
Funciona com qualquer tipo de banco de dados, relacional ou não relacional, ou até com serviços de armazenamento
Casos de uso
-
Cache (mais de 50% dos casos de uso usam armazenamento em cache)
-
Armazenamento de sessões
-
Placares
-
Aplicativos geoespaciais (como serviços de carona)
-
Publicação/assinatura
-
Análise em tempo real
Bancos de dados grafos são bancos de dados NoSQL que usam uma estrutura gráfica para consultas semânticas. O grafo é, basicamente, uma estrutura de dados de índice. Ele nunca precisa carregar ou tocar em dados não relacionados para uma consulta. Nos bancos de dados grafos, os dados são armazenados na forma de nós, bordas e propriedades.
Vantagens
-
Capacidade de fazer mudanças frequentes de esquema
-
Possibilidade de gerenciar volumes enormes e explosivos de dados
-
Tempo de resposta de consulta em tempo real
-
Desempenho superior para consultas de dados relacionados, grandes ou pequenos
-
Atende a requisitos de ativação de dados mais inteligentes
-
Semântica explícita para cada consulta: nenhuma pressuposição oculta
-
Ambiente de esquema online flexível
Casos de uso
-
Detecção de fraudes
-
Redes sociais
-
Mecanismos de recomendação
-
Gráficos de conhecimento
Os bancos de dados de séries temporais (TSDBs) são otimizados para dados de time stamp ou dados de séries temporais. Os dados de séries temporais são muito diferentes de outros workloads de dados pelo fato de que geralmente chegam em forma de ordem temporal, os dados são apenas anexados e as consultas são sempre durante um intervalo de tempo.
Vantagens
-
Ideal para medições ou eventos que precisam ser acompanhados, monitorados e agregados ao longo do tempo
-
Alta escalabilidade para rápido acúmulo de dados de séries temporais
-
Usabilidade robusta para muitas funções, como políticas de retenção de dados, consultas contínuas e agregações com flexibilidade de tempo
Casos de uso:
-
DevOps
-
Monitoramento de aplicativo
-
Telemetria industrial
-
Aplicativos de IoT
Os bancos de dados ledger oferecem um log transparente, imutável e criptograficamente verificável de propriedade de uma autoridade central e confiável. Muitas organizações criam aplicações com semelhantes funcionalidades porque querem manter um histórico preciso dos dados de suas aplicações.
Vantagens
-
Mantém um histórico preciso de dados de aplicações
-
Imutável e transparente
-
Criptograficamente verificável
-
Altamente escalável
Casos de uso:
-
Finanças: manter registro de dados de livros contábeis, como créditos e débitos
-
Manufatura: reconciliar dados entre sistemas de cadeia de suprimentos para acompanhar o histórico completo de manufatura
-
Seguros: acompanhar históricos de transações de reivindicações
-
RH e folha de pagamento: acompanhar e manter um registro de detalhes de funcionários
Os bancos de dados de coluna ampla são bancos de dados NoSQL que usam mapeamento persistente e multidimensional de matrizes esparsas em um formato tabular. Eles podem armazenar grandes volumes de dados coletados, até a escala de PB e acima. Assim como os bancos de dados relacionais, os bancos de dados de coluna ampla usam tabelas, linhas e colunas. No entanto, ao contrário dos bancos de dados relacionais, os nomes e o formato de suas colunas variam de linha para linha na mesma tabela.
Vantagens
-
Bom para grandes volumes de dados
-
Velocidades muito rápidas de gravação
-
Consultas complexas são retornadas rapidamente
-
Os dados são facilmente compactados, economizando espaço e custos
-
Integra-se bem com sistemas existentes
Casos de uso:
-
Aplicativos industriais de grande escala para:
- Manutenção de equipamentos
- Gerenciamento de frotas
- Otimização de rotas
-
Logs de dados
-
Dados geográficos
Conheça histórias de sucesso de bancos de dados na nuvem
Airbnb
A Airbnb migrou seu banco de dados MySQL principal para a nuvem, descobrindo maior flexibilidade e responsividade.
Duolingo
Com seus bancos de dados de nuvem de 31 milhões de itens, a Duolingo obtém 24.000 leituras por segundo.
Os dados estão crescendo exponencialmente
Está cada vez mais difícil processar os dados. Eles crescem exponencialmente, vindo de novas fontes, tornando-se cada vez mais diversos. Com tudo isso, como sua empresa pode capturar, armazenar e analisar dados de maneira rápida o suficiente para continuar competitiva?
Saiba como armazenar, analisar e utilizar melhor o poder de seus dados.
Coloque seus dados para trabalhar com data lakes
As arquiteturas de data lake reúnem data warehousing e análise avançada (inclusive soluções baseadas em machine learning) para ajudar você a obter mais valor dos seus dados. Os data lakes permitem coletar e armazenar quaisquer dados em um repositório centralizado. Isso fornece escala, flexibilidade, durabilidade e disponibilidade ideais. Mas o melhor de tudo é que os data lakes tornam mais rápido o desempenho da análise em todos os seus dados e reduzem o tempo necessário para obter insights desses dados.

Criar um data lake seguro é um desafio
Normalmente, a criação e a implementação de um data lake totalmente produtivo requerem meses de trabalho complicado e tedioso. Você precisa configurar o armazenamento para manipular quantidades enormes de dados, coletar e organizar dados de várias fontes, limpar os dados para prepará-los para uso, configurar e aplicar políticas de segurança complexas, além de encontrar maneiras de facilitar a localização dos dados. Felizmente, há uma solução mais rápida e mais fácil.
Os data lakes da AWS são diferentes
O AWS Lake Formation simplifica o processo de criação de data lakes e automatiza muitas etapas, permitindo que você configure um data lake seguro em dias, não em meses.
-

Configuração mais rápida
Acelere e automatize a mudança, o armazenamento, a catalogação e a limpeza dos dados.
-

Segurança mais ampla
Aplique políticas de segurança entre vários serviços.
-

Mais insights
Capacite seus analistas e cientistas de dados para obter e gerenciar novos insights.
Data lakes permitem muitos tipos de análise
Desde a análise retrospectiva e a geração de relatórios até o processamento aqui e agora em tempo real, passando pela análise preditiva, os data lakes são a opção ideal.
-

Análise operacional e de logs
-

Data warehousing
-
Processamento de big data
-

Streaming e análise em tempo real
-

Análise preditiva
Permita que os usuários finais vejam e visualizem seus dados
Forneça insights aos usuários finais facilmente, quer você esteja criando painéis interativos para sua organização ou incorporando a análise em seus aplicativos ou sites. O Amazon QuickSight é um serviço de inteligência empresarial na plataforma de nuvem que inclui ML Insights. O QuickSight elimina a necessidade de gerenciar servidores ou a capacidade da infraestrutura. Ele tem uma arquitetura sem servidor que permite escalar facilmente para dezenas de milhares de usuários e, com sua opção de definição de preço de pagamento por sessão, você paga apenas pelo que usa.
Obtenha mais insights com o machine learning
Embora o machine learning ainda não tenha atingido todo o seu potencial, atingimos um ponto decisivo: a nuvem tornou o machine learning disponível para empresas de qualquer tamanho.
Machine learning para todos
Com o mais amplo e mais profundo conjunto de recursos de machine learning, a AWS permite que os desenvolvedores e cientistas de dados de todos os níveis de habilidades, mesmo aqueles sem experiência anterior, criem modelos sofisticados. Atualmente, dezenas de milhares de empresas usam a AWS para gerar previsões e análises altamente precisas que revelam insights cada vez mais inteligentes ao longo do tempo.
-
Recursos mais amplos e mais profundos
Crie facilmente aplicações sofisticadas baseadas em IA que incluam visão computacional, linguagem, recomendações e previsão.
-

Nenhuma experiência é necessária
O Amazon SageMaker remove o trabalho pesado de cada etapa do processo de machine learning, facilitando muito a criação, o treinamento, o ajuste e a implantação de modelos.
-

Confiança total
Tenha tranquilidade usando os recursos da AWS, a plataforma de nuvem mais abrangente otimizada para machine learning.
Explore casos de uso de serviços de análise
A INVISTA inova mais rapidamente com a AWS
Ao mudar para data lakes da AWS, a INVISTA reduz o tempo de recuperação de dados de meses para minutos e estende o acesso aos dados a mais usuários.
A Zappos cria experiências inovadoras para os clientes
A Zappos usa os serviços de análise e de machine learning da AWS para fornecer experiências personalizadas que estimulam o engajamento e reduzem as devoluções.
A Woot celebra custos operacionais 90% mais baixos
“Usando o Amazon QuickSight, todos podem criar gráficos e outras visualizações usando apenas o recurso de arrastar e soltar, sem necessidade de conhecimento do SQL.”