Presentación del
volante de inercia de datos
El volante de inercia de datos (Data Flywheel) es un enfoque integral y aditivo para líderes de negocios y tecnología que permite a las organizaciones aprovechar al máximo el valor de sus datos.
Abandonar el uso de
las bases de datos heredadas
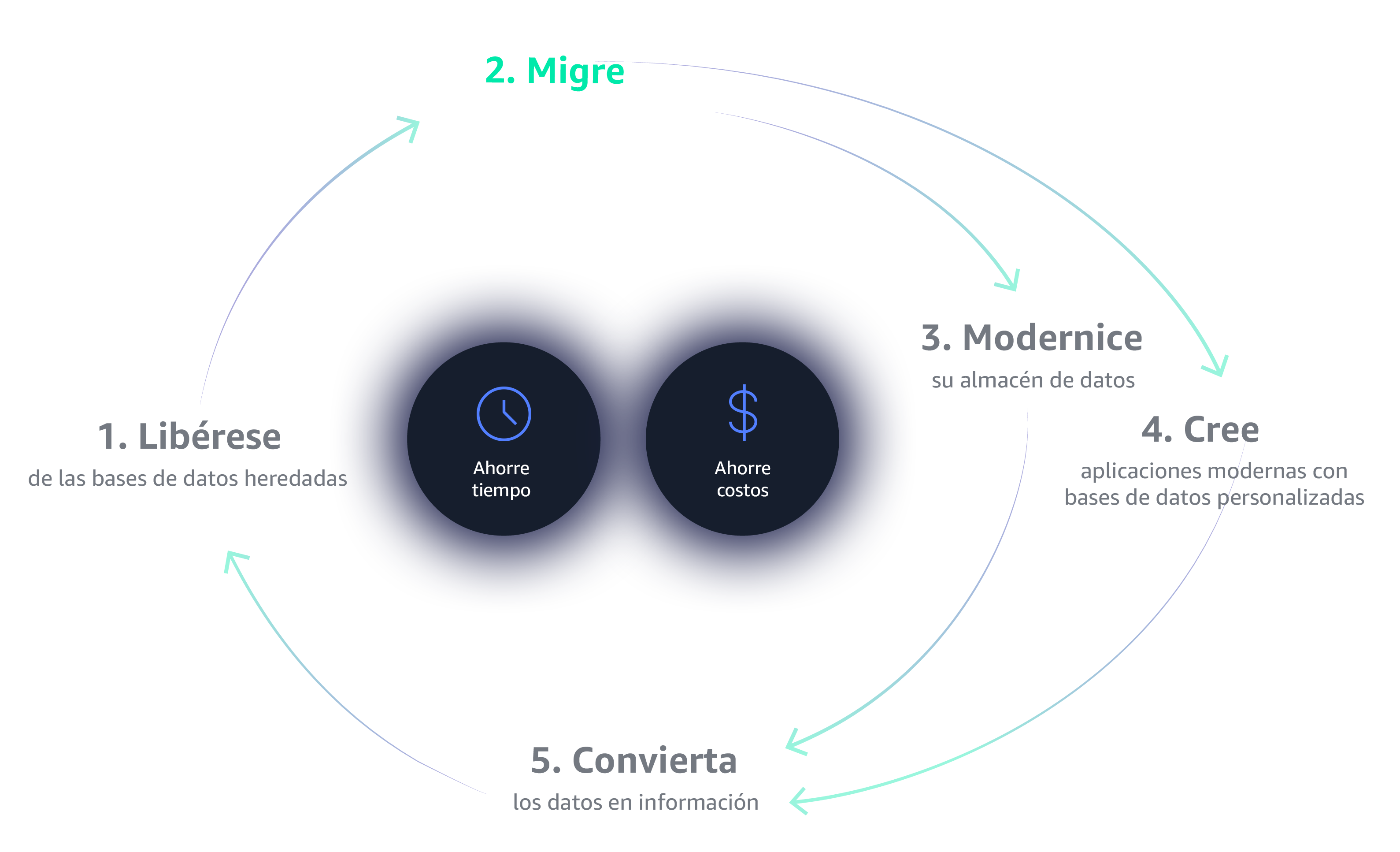
El primer paso para poner en marcha el volante de inercia de datos es liberarse de las limitaciones de las bases de datos heredadas. Las bases de datos heredadas son caras, de propiedad exclusiva, crean dependencia, ofrecen condiciones punitivas de concesión de licencias y conllevan auditorías frecuentes. Por estas y otras razones, las bases de datos heredadas simplemente no pueden ofrecer la escalabilidad, la flexibilidad y la rentabilidad que se necesitan para construir un volante de inercia de datos que pueda lograr con éxito un impulso autosostenido.
Ahorre tiempo y costos con bases de datos y servicios analíticos totalmente administrados
La gestión de sus bases de datos y la infraestructura analítica pueden ser tediosas y consumir mucho tiempo. Migrar a los servicios totalmente gestionados en AWS le permite dedicar tiempo a innovar y construir nuevas aplicaciones en lugar de gestionar la infraestructura.
Ir a lo grande y más rápido con un almacenamiento de datos moderno
Una moderna estrategia de almacenamiento de datos basada en la nube le permite almacenar, procesar y analizar más datos de forma más rápida y eficiente. Es hora de adoptar una arquitectura más flexible, como el lago de datos, un repositorio centralizado que almacena todos los datos y facilita nuevos tipos de análisis.
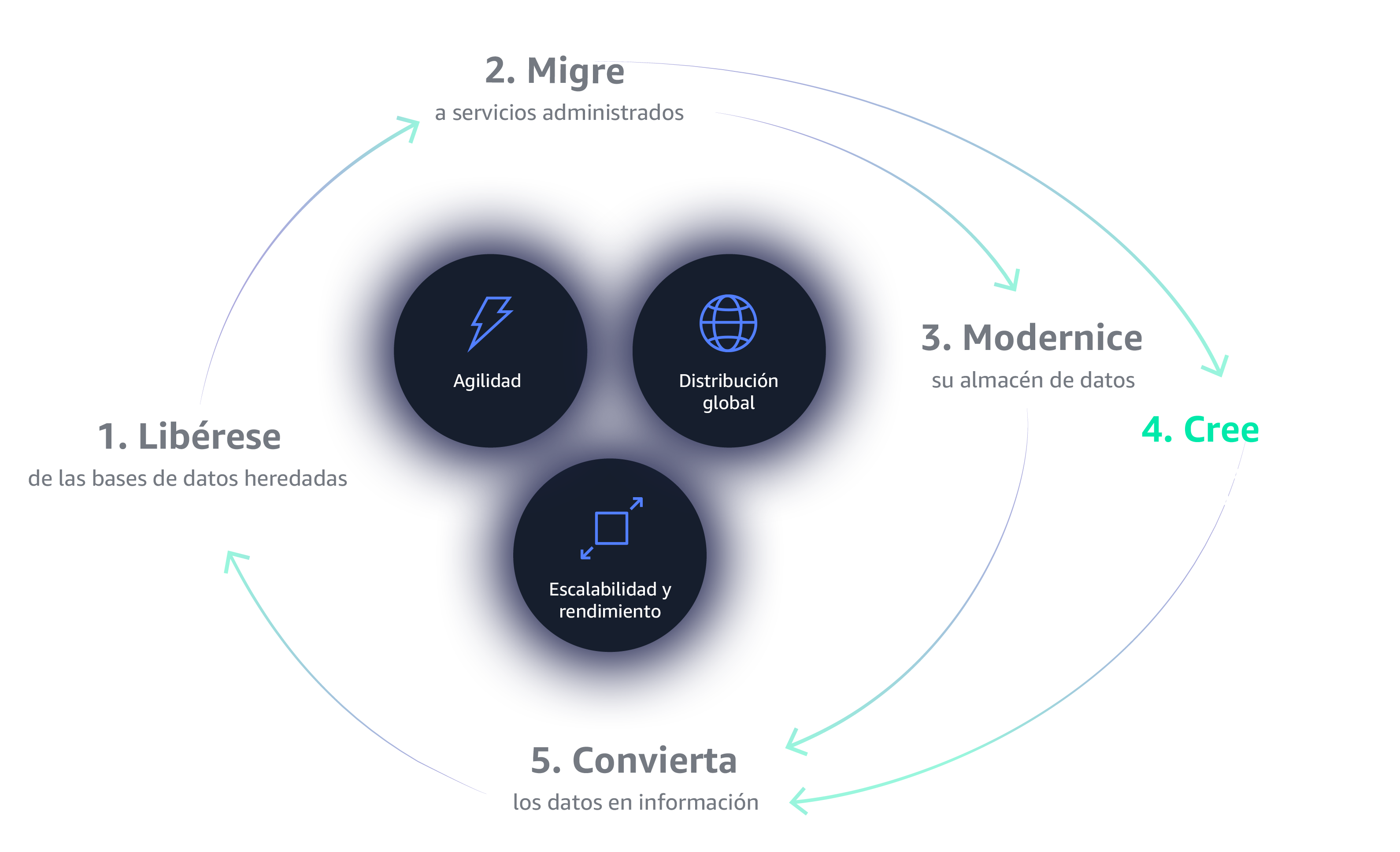
Construir aplicaciones modernas para aumentar el impulso
Construir aplicaciones modernas con más de 15 bases de datos específicas. Proporcione a sus equipos las herramientas adecuadas para el trabajo correcto a fin de crear aplicaciones de alto rendimiento, escalables y disponibles que crecerán junto con su empresa.
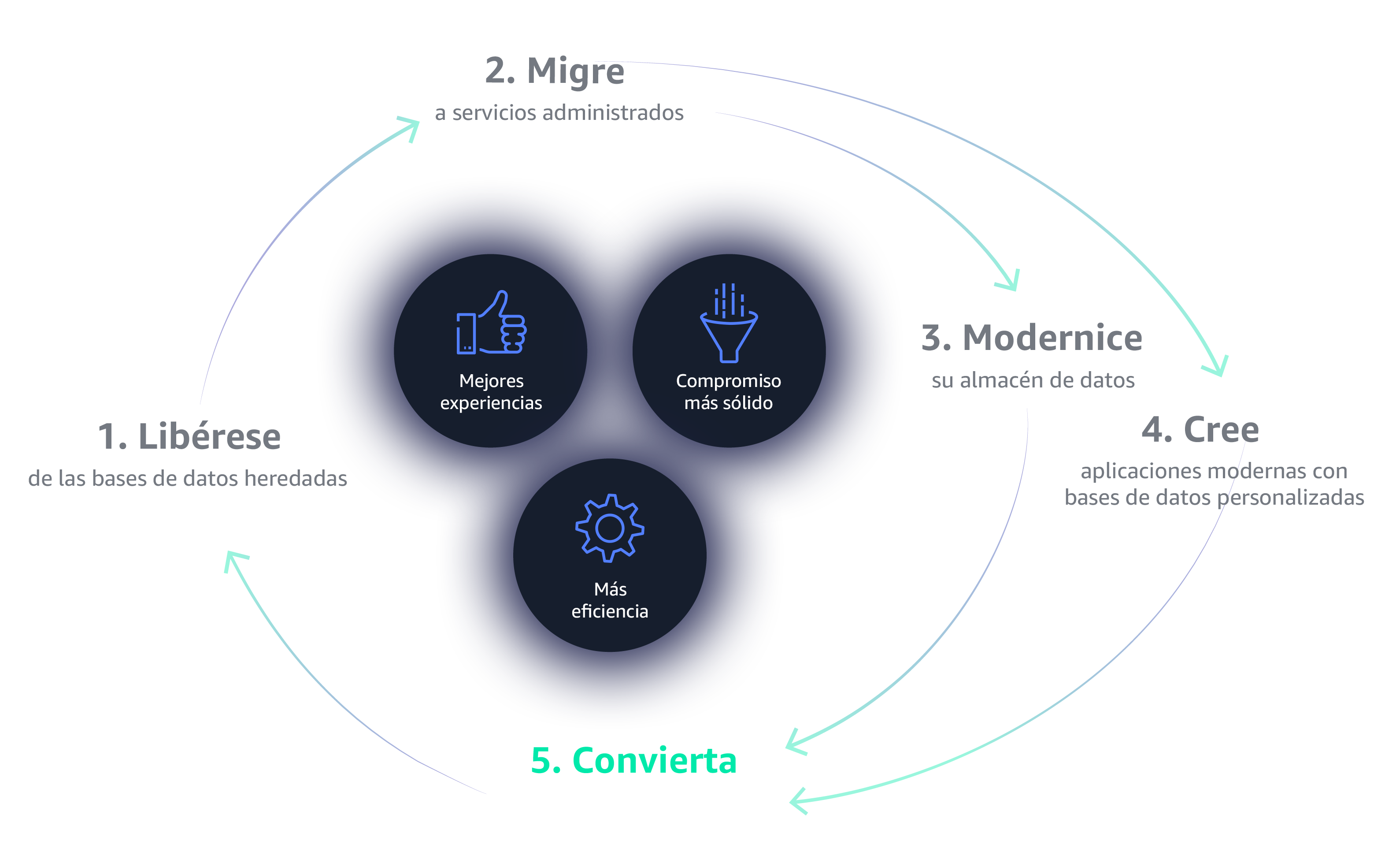
Obtener más valor de sus datos
Sus datos están en la nube, ahora hágalos funcionar para usted. Olvídese de los silos y los análisis incompletos. En la actualidad, las empresas recopilan con mayor rapidez conocimientos inteligentes y precisos a través de lagos de datos, análisis en la nube y aprendizaje automático, y permiten a los usuarios finales visualizar sus datos desde cualquier dispositivo o aplicación.
Crear un impulso de negocios perpetuo
Según la ley de termodinámica, el movimiento perpetuo es imposible. ¿Pero quién dijo que las leyes de la física se aplican a los negocios? Cuando se aplican correctamente, los datos pueden generar un impulso autosuficiente y perpetuamente acelerado para su organización.
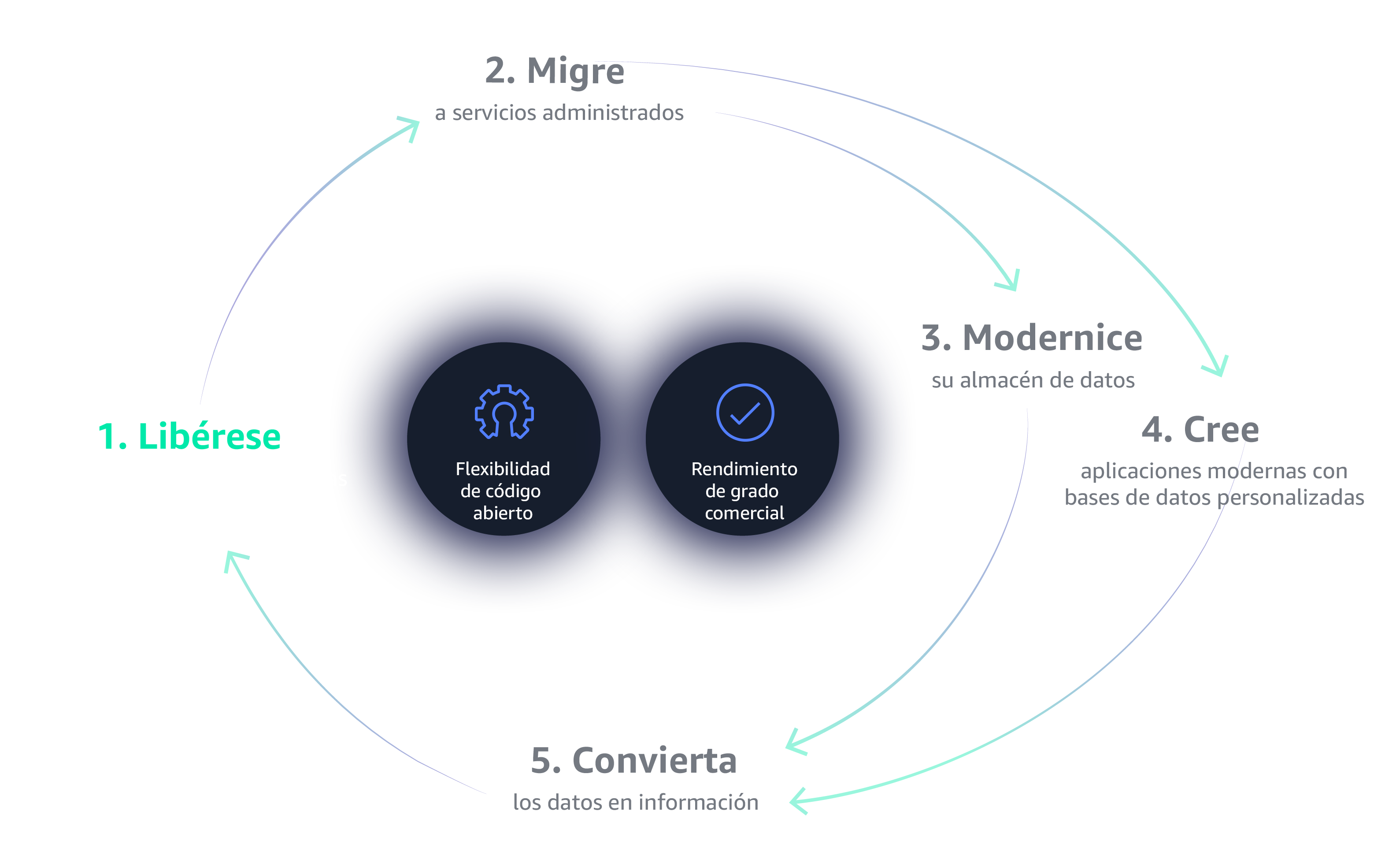
¿Por qué un volante de inercia de datos?
El volante de inercia, como lo popularizó el autor Jim Collins, es un ciclo de retroalimentación compuesto por unas iniciativas clave que interactúan y se potencian de forma mutua para generar un impulso de negocios a largo plazo. A principios de los 90, Jeff Bezos concibió la idea inicial de que Amazon.com utilice el volante de inercia de datos de Amazon, un motor económico que usa el crecimiento y la escala para mejorar la experiencia del cliente a través de más opciones de selección y menores costos.
Creación de un volante de inercia de datos exitoso
Una de las características más singulares del volante de inercia de datos es que no hay "una cosa" que lo impulse, y las organizaciones que buscan una solución tan profundamente básica probablemente perderán el rumbo. El volante de inercia de datos se mueve mediante muchos componentes que actúan en conjunto, lo que equivale a un todo que es mayor que la suma de sus partes. Las organizaciones que se toman el tiempo de desarrollar cada uno de estos componentes, implementando las tecnologías y los procedimientos más relevantes en cada fase, serán las que más se beneficien del volante de inercia de datos.

Proveedores de bases de datos de la vieja guardia
-

Muy costoso
Las bases de datos heredadas son costosas y se termina pagando más por las licencias, el mantenimiento y el soporte.
-

De propiedad exclusiva
La innovación está restringida, ya que se limita a utilizar funciones de base de datos de propiedad exclusiva que coartan la innovación.
-

Dependencia
Los contratos crean dependencia y pueden obligarlo a comprar cosas que no necesita.
-

Condiciones de licencia punitivas
Las complejas licencias contractuales restringen la flexibilidad y añaden costos impredecibles.
-

Auditorías imprevistas
Las auditorías frecuentes pueden añadir costos imprevistos a las implementaciones.
Los clientes migran a
bases de datos de código abierto
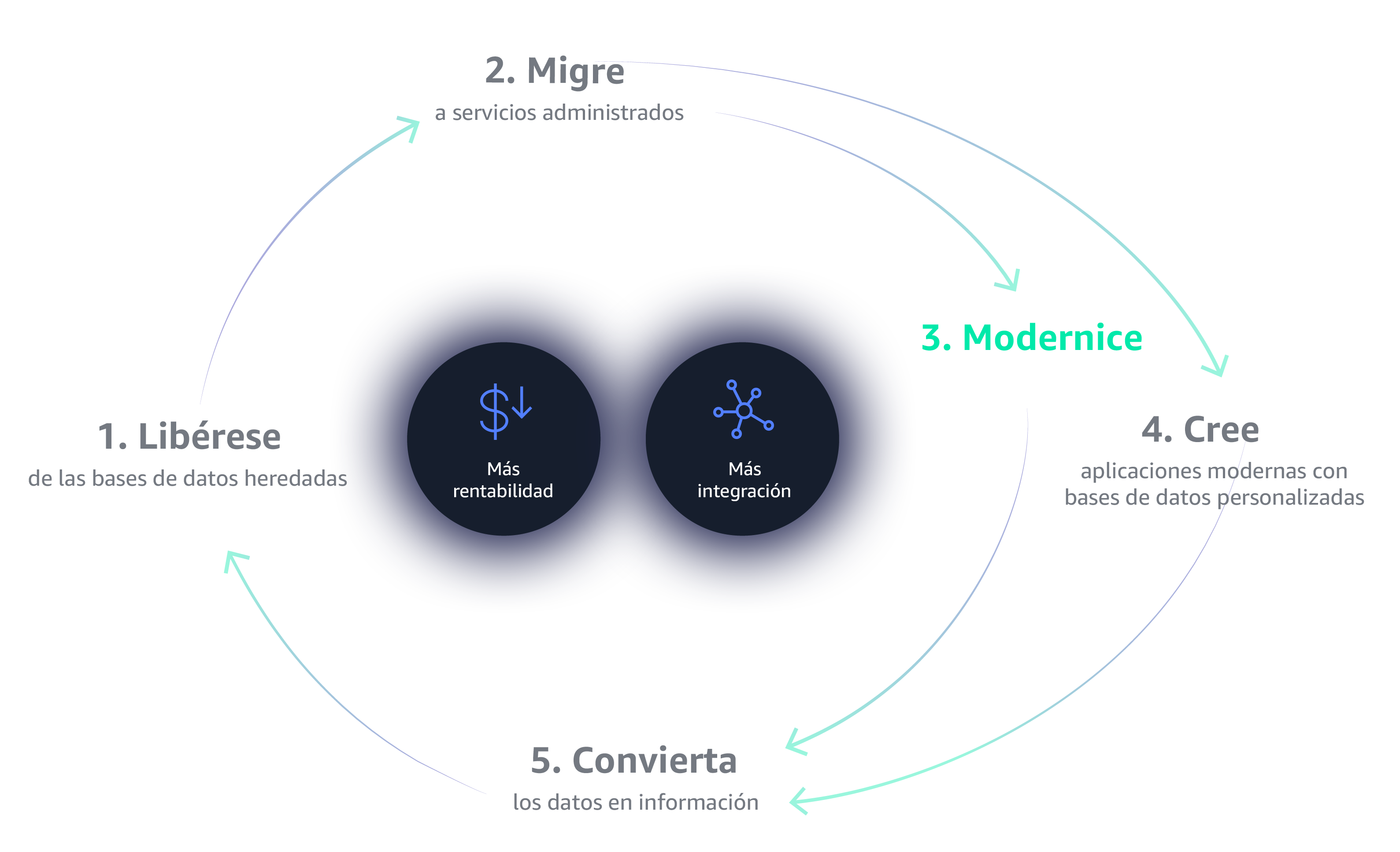
Debido a los retos que se presentan con las bases de datos comerciales de la vieja guarda, los clientes están migrando tan rápido como pueden a alternativas de código abierto, como MySQL, PostgreSQL y MariaDB. Sin embargo, los clientes quieren el rendimiento y la disponibilidad de bases de datos comerciales de alta calidad con la simplicidad y la rentabilidad de las bases de datos de código abierto.
Obenga lo mejor de ambos mundos
Con AWS, puede obtener el rendimiento y la disponibilidad de las bases de datos de calidad comercial con la simplicidad y la rentabilidad del código abierto. Amazon Aurora es una base de datos relacional compatible con MySQL y PostgreSQL que ofrece un rendimiento sustancialmente más rápido que las bases de datos estándar de código abierto a una décima parte del costo de las soluciones de calidad comercial. Amazon DynamoDB es una base de datos de clave-valor y documentación que ofrece un rendimiento de un solo dígito en milisegundos a cualquier escala. Y Amazon Redshift es el almacén de datos en la nube más rápido y rentable disponible.
Explorar historias de clientes que migraron
datos y cargas de trabajo a la nube
Dow Jones libera
fondos para la innovación
Dow Jones migró su plataforma de datos de mercado de los servidores Microsoft SQL a Amazon Aurora, reduciendo los costos en más del 50 %.
Amazon logra liberarse
de las bases de datos
Al migrar cerca de 7500 bases de datos de Oracle a múltiples servicios de bases de datos de AWS con 75 petabytes de datos, Amazon redujo los costos de las bases de datos en un 60 % y la latencia de las aplicaciones orientadas al cliente en un 40 %.
¿Por qué usar bases de datos administradas?
La administración de la base de datos puede convertirse en una gran carga para su empresa. Además de la instalación de hardware y software, hay que preocuparse por los parches de la base de datos, las copias de seguridad, la complicada configuración de los clústeres para la replicación de datos y la alta disponibilidad, la tediosa planificación de la capacidad y el escalado de los clústeres para la informática y el almacenamiento.
Amazon RDS mejora el rendimiento y ahorra tiempo
Las organizaciones a menudo comienzan su transición a los servicios administrados al migrar a Amazon Relational Database Service (RDS), una solución completamente administrada que puede ejecutar los motores de base de datos de su elección, incluyendo motores de código abierto, como MySQL y PostgreSQL, así como Oracle y SQL Server. Amazon RDS mejora la escala y el rendimiento de la base de datos y automatiza las tareas administrativas que requieren mucho tiempo, como el aprovisionamiento de hardware, la configuración de bases de datos, la aplicación de parches y las copias de seguridad.
-

Fácil de administrar
Implemente y mantenga fácilmente el hardware, el sistema operativo y el software de las bases de datos; disfrute del monitoreo incorporado.
-

Rentable y escalable
El cálculo de la escala y el almacenamiento con unos pocos clics y un mínimo de tiempo de inactividad.
-

Disponible y durable
Consiga una réplica automática de datos Multi-AZ y copias de seguridad automatizadas, instantáneas y conmutación por error.
-

Seguridad y conformidad
Cifre los datos en reposo y en tránsito; aprovechar los programas de cumplimiento y garantía de la industria.
Migre todas las bases de datos a la nube
Para obtener aún más beneficios, migre las bases de datos relacionales y no relacionales a los servicios en la nube completamente administrados.

En este libro electrónico, conocerá cómo superar los
límites de arquitecturas de
datos heredados y aprovechar al máximo
los datos.
Bases de datos relacionales
Migre las bases de datos costosas de Oracle y SQL Server a Amazon Aurora. Migre de MySQL y PostgreSQL estándar a Amazon RDS.
Bases de datos no relacionales
Migre almacenamientos de documentación y clave-valor a Amazon DynamoDB, bases de datos de documentos como MongoDB a Amazon DocumentDB y bases de datos de Cassandra a Amazon Keyspaces (para Apache Cassandra).
¿Por qué usar análisis completamente administrados?
Al igual que sus homólogos de bases de datos, los servicios analíticos completamente administrados de AWS reducen los costos y le permiten dedicar más tiempo a la innovación. También permiten escalabilidad dinámica, procesamiento más rápido, visualizaciones más fáciles, mayor disponibilidad y resistencia, y mayor seguridad.
-

Hadoop y Spark
Migrar las implementaciones locales de Hadoop y Spark a Amazon EMR para ahorrar tiempo y costos.
-

Análisis operativo
Elasticsearch, Logstash y Kibana (ELK) locales pueden migrarse a Amazon Elasticsearch Service para ahorrar tiempo y costos.
-
Análisis en tiempo real
Las implementaciones de Apache Kafka pueden migrarse a Amazon Managed Streaming para Apache Kafka (MSK), y Amazon Kinesis puede preparar, cargar y analizar flujos de datos en herramientas analíticas para su uso inmediato.
Explorar historias de éxito de clientes que migraron a bases de datos
y servicios de análisis completamente administrados en la nube
FanDuel logra casi un 100 % de tiempo de actividad
FanDuel migra cargas de trabajo críticas a AWS mediante el uso de Amazon Aurora, logrando casi un 100 % de tiempo de actividad.
Autodesk obtiene nuevos conocimientos con análisis en tiempo real
Con AWS, Autodesk logra mayor visibilidad en sus datos de logística, lo que permite una detección y resolución más rápidas de los problemas.
El almacenamiento de datos tradicional no lo logrará.
Una estrategia tradicional de almacenamiento de datos locales no puede satisfacer las necesidades de la empresa moderna.
-

No se escala
Deberá comprar e instalar un hardware más grande y potente cada vez que alcance los límites de capacidad de almacenamiento y de cálculo.
-

Demasiado lento
Los datos deben migrarse a un sistema de análisis separado antes de ser procesados y analizados, un proceso que es demasiado lento para el análisis en tiempo real.
-

Costoso
Deberá comprar a los proveedores de bases de datos de la vieja guardia, que son costosos, de propiedad exclusiva e imponen condiciones de licencia punitivas.
-

Rígido
No puede acomodar adecuadamente los nuevos tipos de datos generados por sitios web, aplicaciones móviles y dispositivos conectados a Internet.
-
En silos
No incorpora los datos que se almacenan en los lagos de datos o en Hadoop.
-

Complejo
Los análisis se limitan a la presentación de informes operativos sobre los datos históricos mediante un conjunto más reducido de especialistas en BI.
Descubra el almacén de datos en la nube más popular y rápido
La modernización del almacén de datos con Amazon Redshift le ofrece el rendimiento, la escalabilidad y la integración profunda con su lago de datos que necesita para obtener el máximo valor de los datos.
Descubra por qué ahora es el momento de convertirse en una organización impulsada por el análisis y cómo un moderno almacén de datos y una solución de lago de datos pueden contribuir a conseguirlo.
-

Más popular
Miles de clientes usan Amazon Redshift.
-
Integrado
Consulte petabytes de datos en todo el almacenamiento de datos, el lago de datos y las bases de datos operativas.
-

El más rápido
Amazon Redshift es hasta tres veces más rápido que otros almacenes de datos en la nube.
-

Más rentable
Amazon Redshift es, como mínimo, un 50 % menos costoso que otros almacenes de datos en la nube.
Explorar las historias de éxito de almacenamiento de datos moderno
Neilson construye en AWS una plataforma de informes de datos nativa de la nube
Al migrar a una solución de lago de datos de AWS, Nielsen pasó de medir 40 000 hogares a más de 30 millones de hogares cada día.
Equinox impulsa experiencias de cliente personalizadas
AWS ayuda a Equinox a migrar a lagos de datos, logrando análisis potentes y un almacenamiento de datos más flexible.
Cambio en las normas de diseño de aplicaciones
Las aplicaciones modernas imponen un nuevo conjunto de requisitos en las bases de datos. Las aplicaciones actuales necesitan bases de datos para escalar de terabytes a petabytes de datos, admitir millones de usuarios simultáneos y ofrecer un rendimiento con latencia de milisegundos y microsegundos.
Requisitos actuales de las aplicaciones
- Usuarios: más de 1 millón
- Volumen de datos: TB–PB–EB
- Ubicación: global
- Rendimiento: milisegundos, microsegundos
- Tasa de solicitud: millones por segundo
- Acceso: web, móvil, IoT, dispositivos
- Escala: arriba-abajo, fuera-dentro
- Economía: se paga lo que se usa
- Acceso de desarrolladores: acceso inmediato a la API
Almacenar y consertar todos los datos
-

Cambiar la estrategia
El enfoque integral de las bases de datos ya no es suficiente.
-

Desglosar las aplicaciones complejas
Para asegurar una arquitectura y escalabilidad adecuadas, es necesario examinar cada componente de la aplicación.
-
Construir aplicaciones altamente distribuidas
Desglosar las aplicaciones complejas en microservicios.
¿Qué bases de datos son las mejores para sus cargas de trabajo?
La mejor herramienta para un trabajo normalmente difiere según el caso de uso. Por eso los desarrolladores deberían utilizar una multitud de bases de datos específicas para construir aplicaciones altamente distribuidas.
A continuación, explore las ventajas y los casos de uso para las cargas de trabajo de aplicaciones más comunes.
En los sistemas de gestión de bases de datos relacionales (RDBMS), los datos se almacenan en una forma de tabla con columnas y filas, y los datos se consultan mediante el lenguaje de consulta estructurada (SQL). En una tabla, cada columna representa un atributo, cada fila un registro y cada campo un valor de datos. Las bases de datos relacionales son muy populares porque 1) SQL es fácil de aprender y utilizar sin necesidad de conocer el esquema subyacente y 2) las entradas de la base de datos se pueden modificar sin especificar el cuerpo entero.
Ventajas
-
Funciona bien con datos estructurados
-
Compatible con transacciones de ACID y combinaciones complejas
-
Integridad de datos incorporada
-
Precisión y coherencia de datos
-
Indexación ilimitada
Casos de uso
-
ERP
-
CRM
-
Finanzas
-
Transacciones
-
Almacenamiento de datos
Una base de datos de clave-valor utiliza un método simple de clave-valor para almacenar datos como una recopilación de pares de clave-valor en la que una clave sirve como identificador único. Tanto las claves como los valores pueden ser cualquier cosa, desde objetos simples hasta objetos compuestos complejos. Son excelentes para aplicaciones que necesitan escalado al instante para cumplir con cargas de trabajo en aumento o impredecibles.
Ventajas
-
Un formato de datos simple acelera la escritura y la lectura
-
El valor puede ser cualquier cosa, incluidos JSON, esquemas flexibles, etc.
Casos de uso
-
Ofertas en tiempo real
-
Carrito de compras
-
Catálogo de productos
-
Preferencias de los clientes
En las bases de datos de documentos, los datos se almacenan en documentos similares a JSON, y los documentos JSON son objetos de primera clase dentro de la base de datos. Los documentos no son un tipo de datos o un valor, son el punto clave de diseño de la base de datos. Estas bases de datos facilitan a los desarrolladores el almacenamiento y la consulta de datos mediante el mismo formato de modelo de documento que los desarrolladores utilizan en el código de la aplicación.
Ventajas
-
Flexible, semiestructurada y jerárquica
-
La base de datos evoluciona según las necesidades de la aplicación
-
La representación de datos jerárquicos y semiestructurados es fácil
-
Índice potente para una consulta rápida
-
Los documentos se asignan de forma natural a la programación orientada a los objetos
-
Transferencia mucho más fácil de datos a la capa persistente
-
Lenguajes de consulta expresivos creados para los documentos
-
Consultas ad-hoc y agregados en todos los documentos
Casos de uso
-
Catálogos
-
Sistemas de administración de contenido
-
Perfiles de usuarios/personalización
-
Aplicaciones móviles
Con la llegada de las aplicaciones en tiempo real, las bases de datos en memoria que ofrecen acceso rápido a los datos son cada vez más populares. Las bases de datos en memoria fundamentalmente se basan en la memoria principal para el almacenamiento, la gestión y la manipulación de los datos. La memoria se ha popularizado gracias a los programas informáticos de código abierto para el almacenamiento en caché de la memoria, que pueden acelerar las bases de datos dinámicas mediante el almacenamiento de los datos en caché para disminuir la cantidad de veces que una fuente de datos externa debe consultarse.
Ventajas
-
Latencia inferior a milisegundos
-
Puede realizar millones de operaciones por segundo
-
Mejoras importantes en el rendimiento (3 a 4 veces, o más) en comparación con las alternativas basadas en disco
-
Conjunto de instrucciones más simple
-
Compatible con conjuntos de comandos completos
-
Funciona con cualquier tipo de base de datos, relacional o no relacional, o incluso con servicios de almacenamiento
Casos de uso
-
Caché (más del 50 % de los casos de uso son de caché)
-
Almacenamiento de sesión
-
Tablas de clasificaciones
-
Aplicaciones geoespaciales (como servicios que conectan pasajeros con conductores)
-
Pub/sub
-
Análisis en tiempo real
Las bases de datos de gráficos son un tipo de base de datos NoSQL que utilizan una estructura de gráficos para consultas semánticas. El gráfico es, esencialmente, una estructura de datos índice que nunca necesita cargar ni tocar datos no relacionados para una consulta determinada. En las bases de datos de gráficos, los datos se almacenan en forma de nodos, terminales y propiedades
Ventajas
-
Capacidad de hacer cambios frecuentes en los esquemas
-
Puede manejar un enorme y explosivo volumen de datos
-
Tiempo de respuesta de la consulta en tiempo real
-
Rendimiento superior para la consulta de datos relacionados, grandes o pequeños
-
Cumple con los requisitos de activación de datos más inteligentes
-
Semántica explícita para cada consulta, sin suposiciones ocultas
-
Entorno de esquema flexible en línea
Casos de uso
-
Detección de fraudes
-
Redes sociales
-
Motores de recomendación
-
Gráficos de conocimiento
Las bases de datos de series temporales (TSDB) están optimizadas para los datos con marca de tiempo o de serie temporal. Los datos de serie temporal son muy diferentes de otras cargas de trabajo de datos porque normalmente llegan en forma de orden temporal, los datos solo se añaden y las consultas siempre se realizan a lo largo de un intervalo de tiempo.
Ventajas
-
Ideal para mediciones o eventos que son rastreados, monitoreados y agregados a lo largo del tiempo
-
Gran escalabilidad para acumular rápidamente los datos de serie temporal
-
Sólida capacidad de uso para muchas funciones, como políticas de retención de datos, consultas continuas y agregaciones de tiempo flexibles
Casos de uso:
-
DevOps
-
Monitoreo de aplicaciones
-
Telemetría industrial
-
Aplicaciones de IoT
Las bases de datos de libro mayor proporcionan un registro de transacciones transparente, inmutable y verificable mediante criptografía que pertenece a una autoridad central confiable. Muchas organizaciones crean aplicaciones con una funcionalidad similar a la de libro mayor porque desean mantener un historial preciso de los datos de las aplicaciones.
Ventajas
-
Mantiene un historial preciso de los datos de la aplicación
-
Inmutable y transparente
-
Verificable mediante criptografía
-
Alta escalabilidad
Casos de uso:
-
Finanzas: realizar un seguimiento de los datos del libro mayor, como los créditos y los débitos
-
Fabricación: conciliar los datos entre los sistemas de la cadena de suministro para realizar un seguimiento del historial completo de fabricación
-
Seguro: realizar un seguimiento de los historiales de transacciones de reclamos
-
Recursos Humanos y nómina: realizar un seguimiento y mantener un registro de la información de los empleados
Las bases de datos de columnas anchas son bases de datos NoSQL que utilizan un mapeo matricial persistente, multidimensional y disperso en un formato de tabla. Pueden almacenar grandes volúmenes de datos recopilados, hasta y más allá de la escala PB. Al igual que las bases de datos relacionales, las bases de datos de columnas anchas usan tablas, filas y columnas. Sin embargo, a diferencia de las bases de datos relacionales, los nombres y el formato de las columnas puede variar entre las filas de la misma tabla.
Ventajas
-
Buenas para grandes volúmenes de datos
-
Velocidades de escritura muy rápidas
-
Las consultas complejas se resuelven rápidamente
-
Los datos se comprimen fácilmente, lo que ahorra espacio y costos
-
Se integra bien con los sistemas actuales
Casos de uso:
-
Aplicaciones industriales a gran escala para lo siguiente:
- Mantenimiento de equipos
- Administración de flotas
- Optimización de rutas
-
Registros de datos
-
Datos geográficos
Consulte las historias de éxito de bases de datos en la nube
Airbnb viaja por la nube
Airbnb migró su base de datos principal MySQL a la nube y logró mayor flexibilidad y reacción.
Duolingo aprende a gestionar bases de datos con fluidez
Con sus bases de datos de 31 millones de elementos en la nube, Duolingo alcanza 24 000 lecturas por segundo.
Los datos crecen a un ritmo exponencial
Los datos son difíciles de controlar. Su crecimiento es exponencial, proviene de nuevas fuentes, se vuelve más diverso y es cada vez más difícil de procesar. Con todo eso en mente, ¿cómo puede su empresa capturar, almacenar y analizar datos lo suficientemente rápido como para seguir siendo competitiva?
Aprenda a almacenar, analizar y aprovechar mejor el poder de sus datos.
Ponga sus datos a trabajar con lagos de datos
Las arquitecturas del lago de datos reúnen el almacenamiento de datos y la analítica avanzada (incluidas las soluciones impulsadas por el aprendizaje automático) para ayudarlo a obtener más valor de sus datos. Los lagos de datos permiten recopilar y almacenar cualquier dato en un repositorio centralizado. Esto proporciona escalado, flexibilidad, durabilidad y disponibilidad óptimos. Pero lo mejor de todo, es que los lagos de datos hacen que el análisis de todos los datos sea más rápido y reducen el tiempo que se tarda en obtener información de esos datos.

Construir un lago de datos seguro es todo un desafío
Crear e implementar manualmente un lago de datos completamente productivo generalmente requiere meses de trabajo tedioso y complicado. Deberá configurar el almacenamiento para manejar cantidades masivas de datos, recopilar y organizar datos de diversas fuentes, limpiar los datos para prepararlos para su uso, configurar y aplicar políticas de seguridad complejas y encontrar formas de hacer que los datos sean fáciles de ubicar. Afortunadamente, hay una solución más rápida y fácil.
Los datos de lagos en AWS son diferentes
AWS Lake Formation simplifica el proceso de creación de lagos y automatiza muchos pasos, lo que permite establecer un lago de datos seguro en días, no en meses.
-

Configuración más rápida
Acelere y automatice la migración, el almacenamiento, los catálogos y la limpieza de los datos.
-

Mayor seguridad
Aplique las políticas de seguridad en varios servicios.
-

Más información
Empodere a los analistas y científicos de datos para obtener y administrar nueva información.
Los lagos de datos permiten muchos tipos de análisis
Desde el análisis retrospectivo y la presentación de informes hasta el procesamiento aquí y ahora en tiempo real, pasando por el análisis predictivo, los lagos de datos son la elección ideal.
-

Análisis operativo y logístico
-

Almacenamiento de datos
-
Procesamiento de big data
-

Streaming y análisis en tiempo real
-

Análisis predictivo
Habilitar a los usuarios finales a visualizar los datos
Proporcione fácilmente información a los usuarios finales, ya sea que esté construyendo paneles interactivos para su organización o incrustando análisis en sus aplicaciones o sitios web. Amazon QuickSight es un servicio de inteligencia de negocios con tecnología de nube que incluye conocimientos de aprendizaje automático. QuickSight elimina la necesidad de administrar servidores o capacidad de infraestructura. Tiene una arquitectura sin servidores que le permite escalar fácilmente a miles de usuarios, y con su opción de precio flexible de pago por sesión, usted paga únicamente por lo que usa.
Obtenga más conocimiento con el aprendizaje automático
Mientras que el aprendizaje automático aún no ha alcanzado todo su potencial, hemos llegado a un punto de inflexión: la nube ha puesto el aprendizaje automático al alcance de empresas de todos los tamaños.
Aprendizaje automático para todos
Con el conjunto más amplio y profundo de capacidades de aprendizaje automático, AWS permite a los desarrolladores y científicos de datos con cualquier nivel de habilidad, incluso a aquellos sin experiencia previa, crear modelos sofisticados. Miles de empresas que utilizan actualmente AWS para generar predicciones y análisis muy exactos que revelan conocimientos cada vez más inteligentes a lo largo del tiempo.
-
Capacidades más amplias y profundas
¿Construir fácilmente aplicaciones sofisticadas impulsadas por la inteligencia artificial que abarquen la visión por computadora, el lenguaje, las recomendaciones y las previsiones?
-

No se necesita experiencia
Amazon SageMaker elimina el trabajo pesado de cada paso del proceso de aprendizaje automático, haciendo mucho más fácil construir, entrenar, ajustar e implementar modelos.
-

Confianza total
Obtenga tranquilidad al construir en AWS, la plataforma de nube más completa optimizada para el aprendizaje automático.
Explore casos de uso de analíticos puestos en práctica por clientes reales
INVISTA innova más rápido con AWS
Al migrar a lagos de datos de AWS, INVISTA redujo el tiempo dedicado a la recuperación de datos de meses a minutos y amplió el acceso a los datos a más usuarios.
Zappos crea experiencias de cliente innovadoras
Zappos utiliza la analítica de AWS y los servicios de aprendizaje automático para ofrecer experiencias personalizadas que impulsan el compromiso y reducen los retornos.
Woot festeja una reducción del 90 % en costos operativos
“Mediante el uso de Amazon QuickSight, cualquiera puede crear gráficos y otras visualizaciones con solo arrastrar y soltar, sin necesidad de conocimientos de SQL”.